文章基本信息
- 文章名称:Implicit Discriminative Knowledge Learning for Visible-Infrared Person Re-Identification
- 发表会议/年份:CVPR 2024
- 作者:Kaijie Ren, Lei Zhang
- 单位:School of Microelectronics and Communication Engineering, Chongqing University, China
摘要
由于不同相机之间的类内变化和跨模态差异,可见红外人员重新识别 (VI-ReID) 是一项具有挑战性的任务跨模态行人检索任务。现有的工作主要集中在将不同模态的图像嵌入到一个统一的空间中,挖掘模态共享特征。它们只在这些共享特征中寻找独特的信息,而忽略了隐藏在模态特定特征中的身份感知有用信息。为了解决这个问题,我们提出了一种新颖的隐式判别知识学习 (IDKL) 网络来揭示和利用模态特定中包含的隐式判别信息。首先,我们使用一种新颖的双流网络提取特定于模态和模态共享特征。然后,经过净化,在保持身份感知判别知识的同时,减少其模态风格差异。随后,这种隐性知识被提炼成模态共享特征以增强其独特性。最后,提出了一种对齐损失来最小化增强模态共享特征的模态差异。在多个公共数据集上的广泛实验证明了 IDKL 网络优于最先进的方法。代码可在 https://github.com/1KK077/IDKL 获得。
之前工作存在的问题
VI-ReID中的方法可以被分为两类:
- 学习模态共享特征(尽管效果较好,但是无法很好的弥合两个模态之间的模态差距)
- 引入额外的模态信息来弥合模态差距
尽管以上这些模型取得了很好的效果,但是这些模型不可避免地丢弃了一些依赖于特定模态特征的判别信息,这些信息以前没有被充分利用和利用。同时传统的VI-ReID方法涉及蒸馏、对齐和相互学习通常依赖于logits。但是,在测试阶段没有分类器参与,匹配仅在特征级别执行。因此,在特征级别进行判别信息蒸馏也是必不可少的。
主要贡献/创新
为了解决上述限制,在本文中,我们提出了一个隐式判别知识学习 (IDKL) 框架,该框架从特定于模态的特征中捕获隐式不变信息,并将其提炼成模态共享特征以增强其判别能力。我们首先分别使用模态鉴别器和模态混淆器提取模态特定和模态共享特征。模态鉴别器有效地区分了不同的模态特征,赋予它们特定的特征;而模态混淆器无法区分模态特征,从而为它们赋予共享特征。由于前一阶段的模态特定特征包含大量模态差异,不适合直接蒸馏到共享特征中。我们最初使用实例归一化来减少域差异。然而,重要的是要承认 IN 不可避免地会导致某些判别特征的损失。因此,我们的目标是在保留身份感知判别知识的同时减少其模态风格差异。随后,我们通过特征图结构将这种隐式知识提取到特征级别的通道共享特征中,并通过 logit 向量的语义级别以增强其独特性。最后,提出了一种对齐损失来最小化增强模态共享特征的模态差异。
主要贡献可以概括为:
- 我们提出了隐式判别知识学习 (IDKL) 网络来利用模态特定特征中隐含的判别知识来增强模态共享特征的判别能力的上限。
- 为了减少模态风格差异而不丢失模态特定信息的判别信息,我们提出了一种 IN 引导的信息净化器 (IP),它由判别增强损失和差异减少损失监督。
- 提出了一种新的TGSA损失,将判别模态特定信息提炼为模态共享特征,充分缓解模态共享特征的模态间差异。大量的实验结果证明了我们方法的优越性。
方法
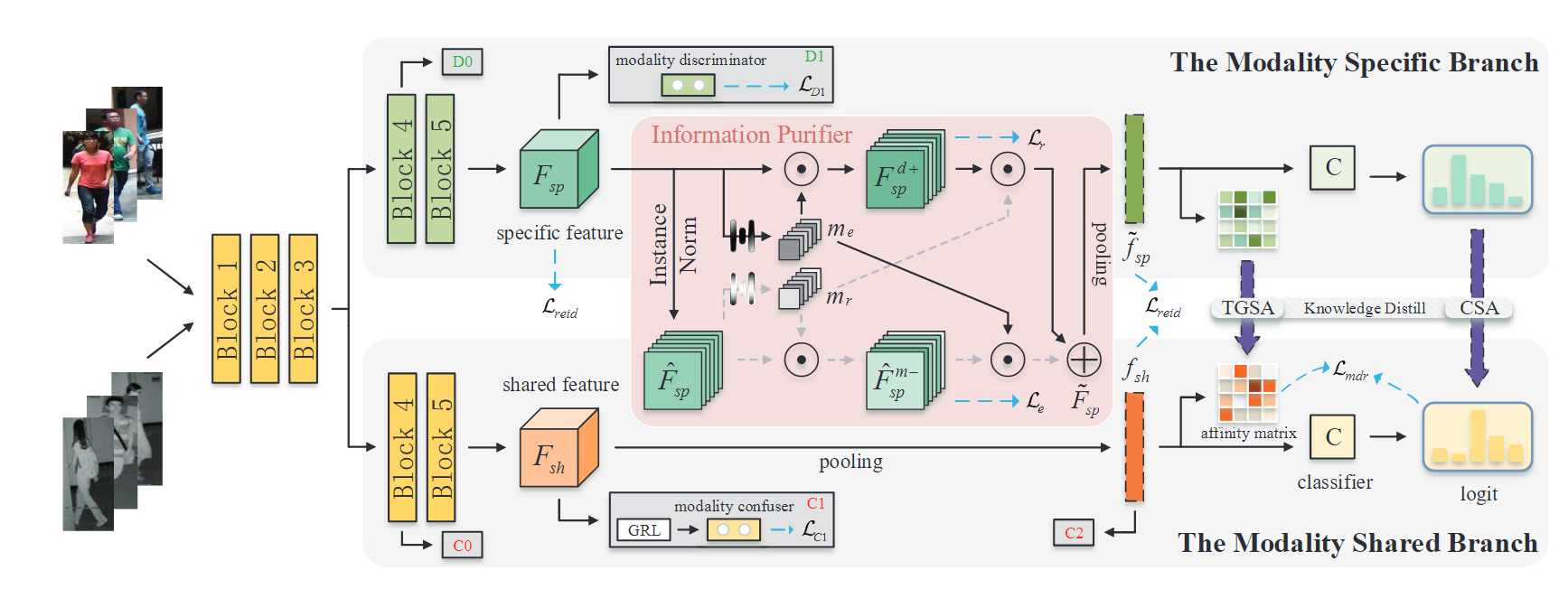
整体流程图

上图展示的IDKL整体流程框架,由ResNet模块构建的双一流网络首先在模态判别器和模态混淆器的约束下提取模态特定特征 (Fsp) 和模态共享特征 (Fsh),同时使用常规的ReID损失来基本优化网络。然后,将模态特定特征输入信息净化器以调节模态样式差异,同时保留隐式判别信息并获得净化的模态特定特征 (F~sp)。随后,这些隐式知识通过Triplet Graph Structure Alignment(TGSA,在feature-level)和Class Semantic Alignment(CSA,在logit-level)蒸馏到模态共享特征中。最后,提出了 Lmdr 以最小化增强模态共享特征内的模态差异。
特征提取
首先将可见光和红外图片分别表示为:
V={xiV}i=1NVI={xiI}i=1NI
其中NV=NI=N,表示从一个mini_batch中采样的红外和可见光照片数量N=P×K(P代表的是人物ID数量,K代表的是每个ID所选择的图片数量),因此一个mini-batch中一共包含2N张照片。
然后所有的照片X首先会送入双流network中来提取模态独特特征Fsp(Fsp,V和Fsp,I)和Fsh(Fsh,V和Fsh,I),使用下式表示:
Fsp=Esp(x∣Θ,Ψ)Fsh=Esh(x∣Θ,Φ)
提取器E是ResNet50,average pooling被替换为Gem pooling,Θ代表的是ResNet50前三个阶段的网络参数,Ψ,Φ代表的是ResNet50最后两个个阶段的网络参数。
模态混淆器和鉴别器
模态混淆器
使用了一种基于梯度反转层(GRL)的对抗性模态分类器作为“模态混淆器”。
LCj=−2N1i=1∑2Nti⋅logp(Cj(GRL(Fshi))),
模态鉴别器
为了充分学习与模态相关的信息,我们使用模态分类器作为模态鉴别器。此不使用 GRL 的分类器应用于特定分支以提取特定于模态的特征。分类损失公式如下:
LDj=−2N1i=1∑2Nti⋅logp(Dj(Fspi)),
两个模块的总损失可以表示如下:
LC=j=1∑KLCj,LD=j=1∑KLDj
为了有效地提取特定于模态和模态共享特征,我们将这些模态分类器损失与标准 ReID 损失 Lreid 相结合,其中包括交叉熵和硬三元组损失。这些应用于特定于模态和模态共享分支,如下所示:
Lsp=Lreid(fsp)+LD,Lsh=Lreid(fsh)+LC
其中f∈RB×C代表的是F∈RB×C×H×W经过pooling后的结果。
最终我们模型的基本损失可以表示为:
Lb=Lsh+Lsp
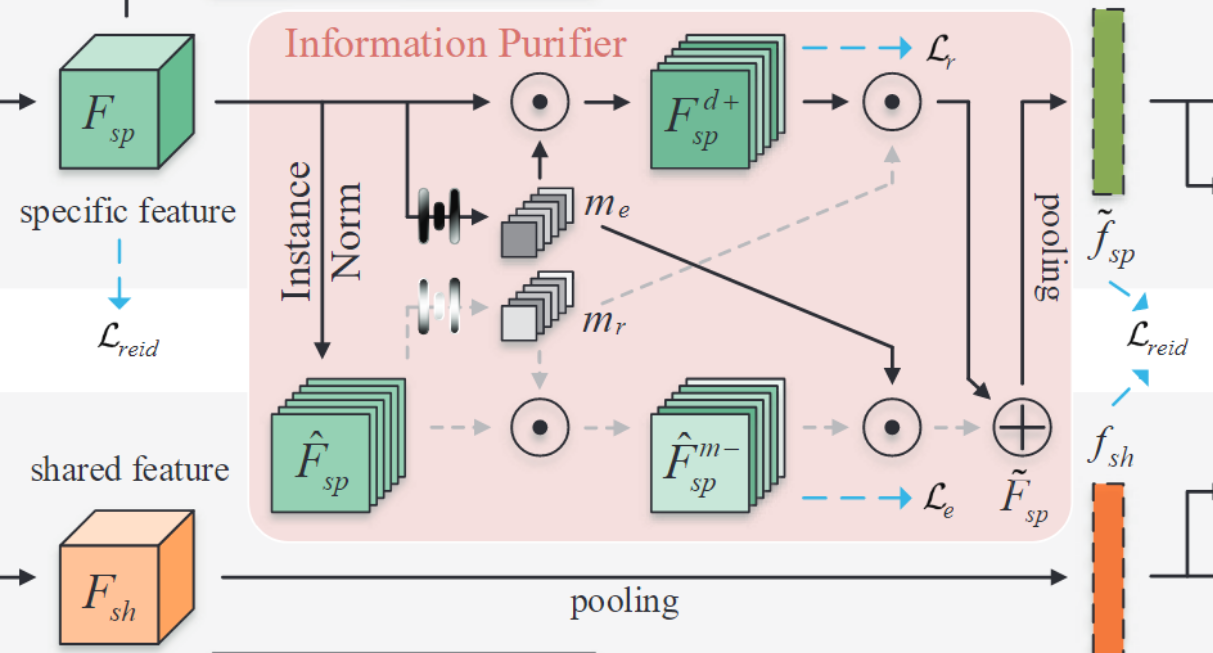
信息净化器 (IP) 旨在最小化风格方差的影响,同时保留特定模态特征中的身份感知和判别知识。IP集成了实例归一化(IN),众所周知,它可以减少域差异。然而,重要的是要认识到 IN 不可避免地导致一些判别特征的损失,这可能会阻碍 ReID 的高性能。
首先对Fsp使用IN得到F^sp:
F^sp=IN(Fsp)=Var[Fsp]+ϵFsp−E[Fsp]
然后同SENet的方法一样,我们生成了两个channel-wise的masks me和mr:
me=σ(W2δ(W1g(Fsp))),mr=σ(W4δ(W3g(F^sp))),
他们的作用分别是,me代表的是增强判别特征,mr代表的是减少attention mask的差异(reduction of discrepancies attention mask)。所以我们可以得到更强的特殊特征Fspd+,以及更小的模态差异特征F^spm−(计算如上图所示)
随后,我们计算判别增强损失(discrimination enhancing loss)Le和差异减少损失(discrimination enhancing loss)Lr分别用于监督me与mr的生成:
Le=Softplus(h(Csp(fspd+))−h(Csp(fsp)))
Lr=Softplus(d(f^sp,Vm−,f^sp,Im−)−d(f^sp,V,f^sp,I))
这里Le希望能够生成比Fsp更具有区别性特征的Fspd+,Lr则希望生成的F^spm−相比F^sp有更小的模态差异。
Softplus(⋅)=ln(1+exp(⋅)),旨在是损失函数都限制为正数
最后将他们结合起来就可以得到purified modality-specific feature:
F~sp=me⊙F^spm−+mr⊙Fspd+.
最后这一模块的损失函数可以表示为如下形式:
Lip=Le+Lr+Lreid(f~sp)
隐式知识蒸馏(IKD)
为了确保模态共享特征全面学习和集成隐式信息,我们通过 TGSA 从 feature 级别以及CSA 从 logit 级别执行蒸馏。
Triplet Graph Structure Alignment (TGSA)
为了赋予共享特征以区分性信息并在特征层面减少模态差异,我们开发了一种三元特征图结构对齐损失。这种方法的动机源于特征图结构包含丰富的关于特征之间关系和分布的信息,例如类间区分性和类内多样性。这些特性被用来挖掘潜在的特征关系并在[17, 36]中增强特征表示。表示特征之间关系的图结构亲和矩阵计算如下:
αij=∑k∈Niexp(L([l(fi)∥l(fk)]⋅w))exp(L([l(fi)∥l(fj)]⋅w)),
其中L代表的是LeakyReLU,[⋅∣∣⋅]代表的是拼接操作,Ni表示用于为第 i 个样本归一化的邻居样本。l(⋅)是特征维度转化层,w是全连接层。
由于我们利用图结构来对齐和提取知识,而不是增强特征,并且欧氏空间分布对特征更具意义,因此我们用欧氏距离代替线性变换来计算注意力分数,并重新定义两组特征的图结构表达如下:
A(a;b)={αij}i,j∈N=∑k∈Nexp(D(fai,fbk))exp(D(fai,fbj)),
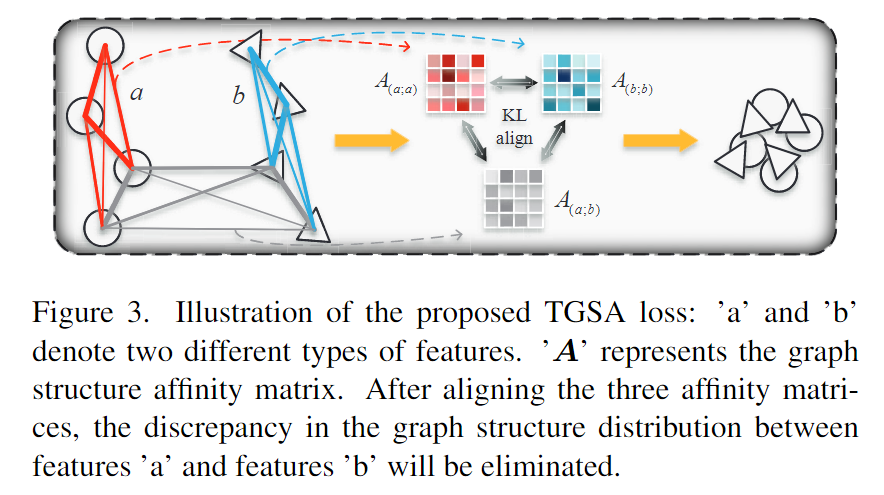
具体而言,三元组图结构对齐损失Ltgsa 是专为跨模态重识别(ReID)开发的,用于对齐两种不同的模态类型,使它们能够符合相同的图结构分布并减少模态差异。该损失包含两个自模态亲和矩阵和一个跨模态亲和矩阵,后者确保了图结构分布的整体一致性,如图3所示。通过使用Kullback-Leibler(KL)散度,这三个矩阵成对对齐。因此,两种不同模态类型的对齐损失 ( Ltgsa ) 定义为:
Ltgsa(a;b)=p=1∑Pk=1∑K(KL(A(a;a)pk,A(b;b)pk)+KL(A(a;a)pk,A(a;b)pk)+KL(A(a;b)pk,A(b;b)pk)).
其中Apk代表的含义是第p个人的第k个样本的图分布。
为了将判别隐式模式特定知识传达为特征级共享特征,通过TGSA在同质特征上的两个分支上的蒸馏损失可以表示为:
Ltgsa(a;b)=p=1∑Pk=1∑K(KL(A(a;a)pk,A(b;b)pk)+KL(A(a;a)pk,A(a;b)pk)+KL(A(a;b)pk,A(b;b)pk)).
Class Semantic Alignment(CSA)
CSA用于将隐式模态特定知识的语义信息提取到模态共享分支中,以增强共享特征的特征表示。CSA 在 logit 级别对两个分支之间的同质特征进行操作。分类器背后的 logit 矩阵可以表述为:
Zsp=Csp(fsp),Zsh=Csh(fsh),
CSA损失和之前的TGSA损失非常的相似,可以表示为下式:
Lcsa=i=1∑N(KL(Zsh,Vi,Zsp,Vi)+KL(Zsh,Ii,Zsp,Ii)).
模态差异减少损失(MDR)
Modality Discrepancy Reduction (MDR)的目标是为了保证模态共享特征的不变表示,进一步利用TGSA和CSA来减少模态共享分支内的模态差异,如下所示:
Lmdr=Ltgsa(sh,V;sh,I)+i=1∑NKL(Zsh,Vi,Zsh,Ii).
这样,模态共享分支的可见特征和红外特征可以从特征级和语义级实现相互学习。它使两种模态特征相互对齐,同时减轻模态差距并保持模态共享特征的不变性。
综上,一共分别对齐了:
- 红外模态sh和sp(logit+feature)
- 可见光模态sh和sp(logit+feature)
- 双模态的sh(logit+feature)
优化
最终,通过从特定于模态的特征中连续提取隐式判别知识,并始终减少模态共享特征中的模态差异,我们可以获得更具辨别力和不变的模态共享特征。
IDKL的最终优化函数可以被表示为如下所示:
Ltotal=Lb+λ1Lip+λ2Ltgsa+λ3Lcsa+Lmdr,
其中,λ1,λ2,λ3为超参数。
实验结果
展示出来结果非常不错,但是如果
总结
idea非常不错,首次使用双分支网络对共享和特有特征进行提取的思路很好,但是文章没有提自己使用了rerank策略使其效果增长了10个点的事情,以及GRL并没有真正在代码中使用过,感觉文章大小问题还是有些多。