文章基本信息
- 文章名称:Diverse Embedding Expansion Network and Low-Light Cross-Modality Benchmark for Visible-Infrared Person Re-identification
- 发表会议/年份:CVPR 2023
- 作者:Yukang Zhang, Hanzi Wang
- 单位:Fujian Key Laboratory of Sensing and Computing for Smart City,School of Informatics, Xiamen University, 361005, P.R. China.2Key Laboratory of Multimedia Trusted Perception and Efficient Computing,Ministry of Education of China, Xiamen University, 361005, P.R. China.3Shanghai Artificial Intelligence Laboratory, Shanghai, 200232, China.
摘要
对于可见光-红外行人重识别(VI-ReID)任务,主要挑战之一是可见光(VIS)和红外(IR)图像之间的模态差距。然而,训练样本通常有限,而模态差距过大,导致现有方法无法有效挖掘多样化的跨模态线索。为了解决这个限制,我们在嵌入空间中提出了一种新颖的增强网络,称为多样化嵌入扩展网络(DEEN)。所提出的 DEEN 可以有效地生成多样化的嵌入来学习信息丰富的特征表示并减少可见光和红外图像之间的模态差异。此外,VIReID模型可能会受到剧烈光照变化的严重影响,而所有现有的VIReID数据集都是在足够的光照下捕获的,没有明显的光照变化。因此,我们提供了一个低光跨模态(LLCM)数据集,其中包含由 9 个 RGB/IR 相机捕获的 1,064 个身份的 46,767 个边界框。在 SYSU-MM01、RegDB 和 LLCM 数据集上进行的大量实验表明,所提出的 DEEN 相对于其他几种最先进的方法具有优越性。代码和数据集发布于: https://github.com/ZYK100/LLCM
之前工作存在的问题
之前方法主要通过两种类型的方法来减少VI-ReID问题中所存在的模态差异。特征级方法,图像级方法。但是这些方法存在以下问题:
- 特征级方法,由于模态差异大,无法直接投入到一个共享空间中去
- 虽然图像级方法可以减少模态差异,但生成的跨模态图像通常伴有噪声,这是由于缺乏VIS-IR图像对所致。
主要贡献/创新
- 提出了一种新颖的多样化嵌入扩展(DEE)模块,具有中心引导对挖掘(CPM)损失,以生成更多嵌入来学习多样化的特征表示。我们是第一个在 VIReID 的嵌入空间中增强嵌入的人。此外,我们还提出了一种有效的多级特征聚合(MFA)块来挖掘潜在的通道和空间特征表示。(DEE MFA CPM)
- 通过将 DEE、CPM 损失和 MFA 纳入端到端学习框架,我们提出了一种有效的多样化嵌入扩展网络(DEEN),可以有效减少 VIS 和 IR 图像之间的模态差异。
- 我们收集了一个低光跨模态(LLCM)数据集,其中包含在光照变化和低照度环境下捕获的 1,064 个身份的 46,767 张图像。 LLCM数据集具有更多新的重要特征,可以促进VIReID研究走向实际应用。
- 大量实验表明,在三个具有挑战性的数据集上,所提出的 DEEN 优于 VIReID 任务的其他最先进方法。
方法
整体流程图
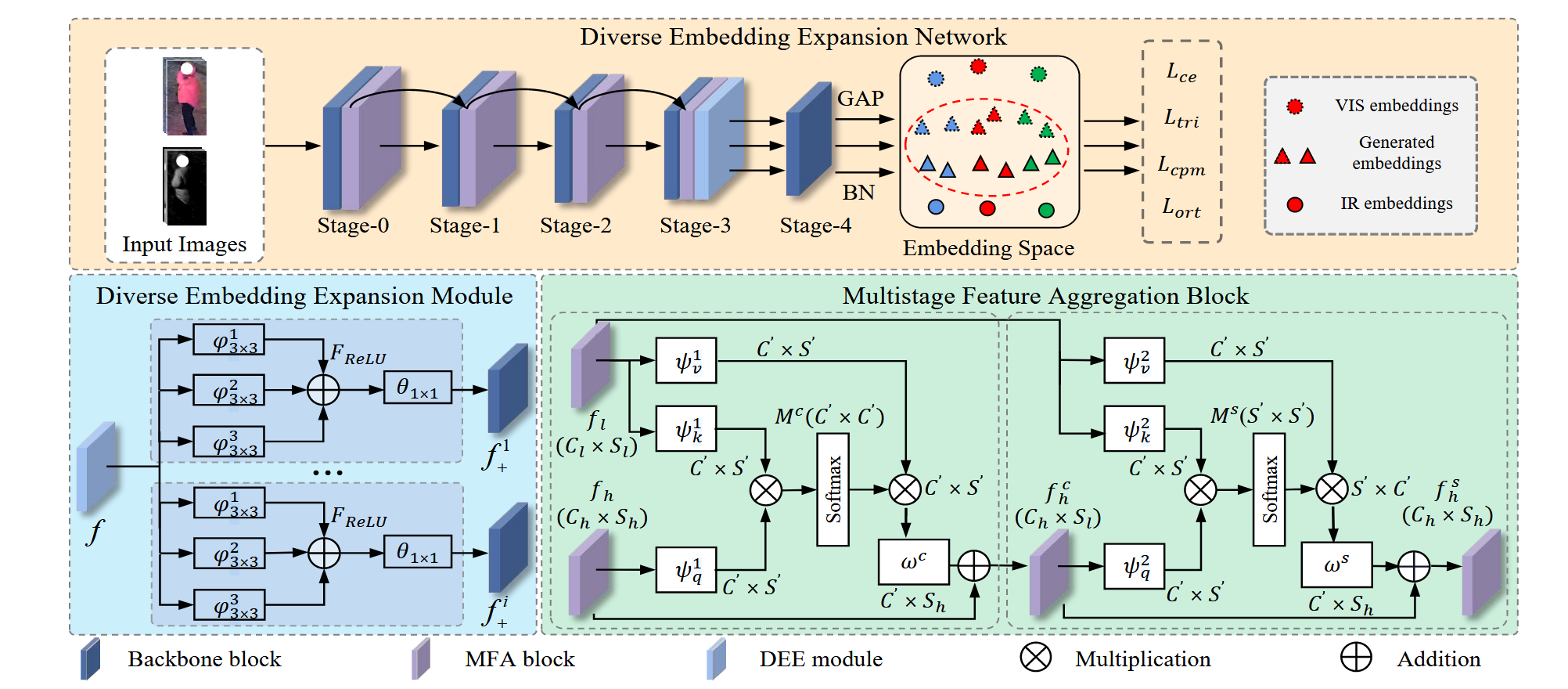
上图展示了所提DEEN网络的流程框架,包括 DEE 模块和 MFA 块。 DEE 模块可以通过新颖的 CPM 损失生成更多嵌入,以学习不同的特征表示。 MFA 块可以聚合来自不同阶段的嵌入,以挖掘不同的通道和空间特征表示。
模型架构
上图概述了所提出的多样化嵌入扩展网络(DEEN),该网络利用双流 ResNet-50 网络作为主干。VIS-IR 特征被馈送到所提出的多样化嵌入扩展(DEE)中模块来生成更多嵌入。然后,提出了中心引导对挖掘(CPM)损失,以使生成的嵌入尽可能多样化,以学习信息丰富的特征表示。此外,我们采用有效的 MFA 块来聚合不同阶段的特征,以挖掘不同的通道和空间特征交涉。在训练阶段,批量归一化(BN)层之前和之后的所有特征都被输入到不同的损失中,以共同优化 DEEN。
Diverse Embedding Expansion Module(DEE)
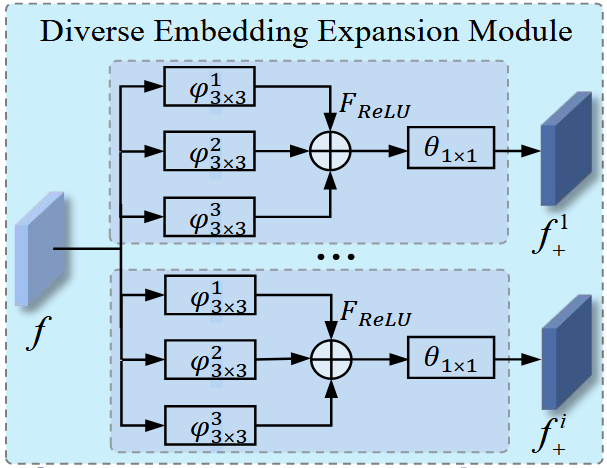
所提出的DEE模块用于生成更多的嵌入,以缓解由于训练数据不足而带来的问题,该模块使用多分支卷积生成结构。具体来说,对于每个DEE分支,我们首先使用三个3x3的膨胀卷积层、、,这些层具有不同的膨胀比率(1, 2, 3),以将特征图 的数量减少到其自身大小的1/4,然后我们通过将这些特征图合并成一个特征图来获得特征图,接着通过ReLU激活层 来提高DEE的非线性表示能力。然后,将另一个卷积层 应用于获得的特征图以改变其尺寸与 相同。因此,第 个分支生成的嵌入 可以写成如下形式:
然后,所有生成的嵌入被连接在一起并用作骨干网络下一阶段的输入。
代码实现如下:
1 | class DEE_module(nn.Module): |
FCnm的主要差别在不同的dilation和不同的padding大小
Center-Guided Pair Mining Loss(CPM)
从上面的操作可以看出,DEE 模块只能使用多分支卷积块生成更多的嵌入。然而,该操作无法有效地获得多样化的嵌入。因此,我们应用以下三个属性来限制生成的嵌入尽可能多样化,以有效减少可见光和红外图像之间的模态差异:
- 生成的embedding应该尽可能多样化,以有效地学习信息丰富的特征表示。(意味目标函数需要拉开生成embedding和原始embedding之间的距离)
- 生成的embedding应有助于减少可见光和红外图像之间的模态差异。(意味目标函数需要拉近VIS生成embedding和IR原始embedding的距离,以及 IR生成embedding和VIS原始embedding的距离)
- 类内距离应该小于类间距离(由于上面第二点的作用,可能会导致不同的模态之间的距离会小于相同模态之间的距离。这是不好的,需要满足第三点)。
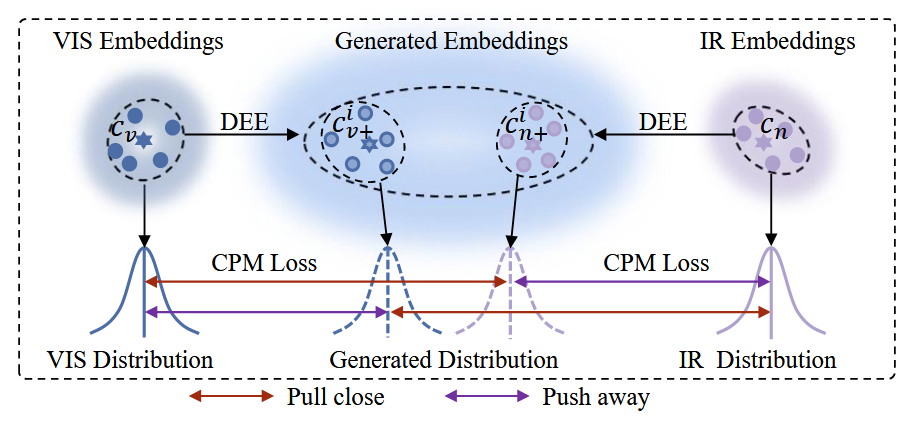
上图为CPM的工作示意图,对于由VIS模态生成的嵌入,CPM损失可以表示为:
其中 是两个嵌入之间的欧几里得距离。 和 是来自VIS和IR模态的原始嵌入, 是从VIS模态的第i个分支生成的嵌入。j和k是minibatch中的不同身份,且 。在公式(2)中,第一个项可以将生成的嵌入 向原始IR的嵌入 拉近,以减少 和 之间的模态差异。第二项可以将生成的嵌入 推离VIS的嵌入 ,以使 学习到信息丰富的特征表示。第三项可以使类内距离小于类间距离。
然后,我们使用每个类的嵌入中心 和 来使生成的嵌入中心 和 更具判别力,并引入一个边距项 来平衡公式(2)中的三个项。因此,对于来自VIS的嵌入,CPM损失表示为:
类似地,对于由IR生成的嵌入的类中心 ,我们有:
因此,最终的CPM损失可以表示为:
此外,为了确保不同分支生成的嵌入能够捕获不同的信息丰富的特征表示,我们强制这些不同分支生成的嵌入彼此正交,以最小化重叠元素。因此,正交损失可以表示为:
其中分别代表的是第几个分支生成的embedding。
我们认为通过正交损失可以强制生成的嵌入学习更多信息的特征表示。
Multistage Feature Aggregation Block(MFA)
不同层次特征的聚合已被证明对语义分割、分类和检测任务有帮助。为了从不同阶段聚合特征以挖掘多样的通道级和空间特征表示,我们结合了一个有效的通道-空间多阶段特征聚合(MFA)模块,以聚合多阶段特征,灵感来自于。
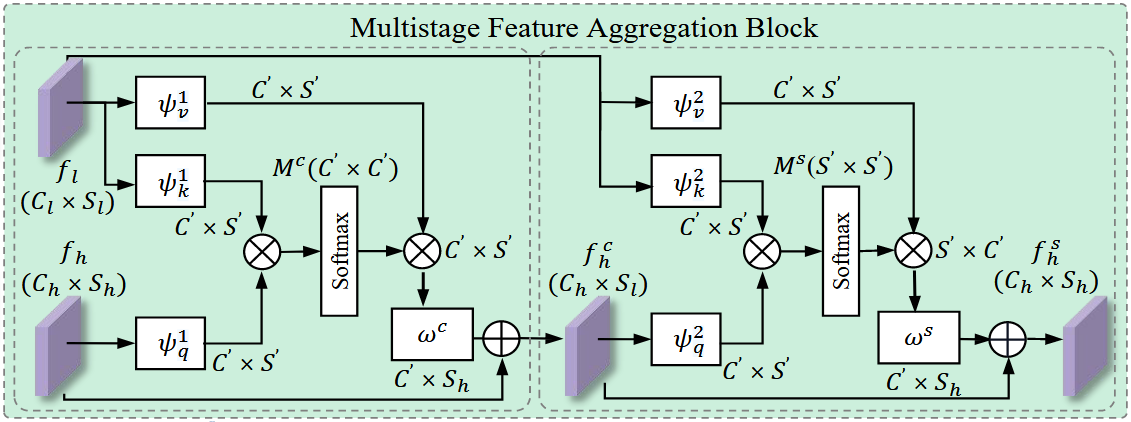
接下来,我们详细阐述了MFA模块的细节,如上图所示。具体来说,我们在骨干网络的每个阶段为通道-空间聚合模块考虑了两种类型的源特征:阶段前的低级特征图 和阶段后的高级特征图 ,其中C、W和H分别表示通道数、宽度和高度。首先,我们使用三个1x1卷积层 将 转换为三个紧凑的嵌入:, 和 。然后,通过矩阵乘法和softmax计算通道相似度矩阵 :
因此,我们通过矩阵乘法恢复 和 的通道维度来实现通道级多阶段特征聚合。在这之后,另一个1x1卷积层 被应用于将上述特征图的尺寸转换为 的尺寸。最后,我们通过矩阵加法将 加到它上面来获得输出:
之后,通过上述操作获得的 和低级特征图 被用来执行空间特征聚合操作,这类似于通道级多阶段特征聚合操作。最后,我们得到MFA的输出如下:
其中 和 是两个1x1卷积层, 是空间相似度矩阵。
Multi-Loss Optimization
除了所提出的 和 外,我们还结合了交叉熵损失 和三重态损失 以端到端的方式联合优化网络,通过最小化这四个损失的总和 ,其公式如下:
其中 和 是控制损失项相对重要性的系数。
LLCM数据集
简介

在本文中,我们收集了一个新的具有挑战性的低光跨模态数据集,称为 LLCM 数据集。 LLCM数据集利用部署在弱光环境中的9个摄像头网络,可以在白天捕获VIS图像,在夜间捕获IR图像。为了保护个人隐私信息,我们利用 MTCNN来获取人脸的边界框并模糊这些区域。我们确保每个带注释的身份都被可见光和红外摄像机捕获。上图显示了 LLCM 数据集的一些示例。与现有的VIReID数据集相比,LLCM数据集具有以下新的重要特征:首先,LLCM数据集中的图像是在VIS和IR模态的复杂低光环境下捕获的,其中包含严重的光照变化和是现实场景中常见的问题。如上图所示,恶劣的光照条件会改变人衣服的颜色并导致衣服纹理信息的丢失,这给VIReID带来了巨大的挑战。其次,LLCM 数据集具有大量的身份和边界框。该数据集包含 1,064 个身份的 46,767 个边界框,使其成为目前最大的 VIReID 数据集。第三,LLCM数据集是从一月到四月的100多天收集的,考虑了不同的气候条件和布料风格。长期数据收集有助于研究不同气候和服装风格下的 VIReID 任务,从而增加了 VIReID 模型的泛化性。
评估协议
我们将LLCM数据集按约2:1的比例划分为训练集和测试集。训练集包含30,921个边界框,共713个身份(其中16,946个边界框来自可见光(VIS)模态,13,975个边界框来自红外(IR)模态);测试集包含13,909个边界框,共351个身份(其中8,680个边界框来自可见光模态,7,166个边界框来自红外模态)。与RegDB数据集相似,我们使用从可见光到红外(VIS to IR)和从红外到可见光(IR to VIS)两种模式评估VI-ReID模型的性能。在测试阶段,我们随机选择每个身份的一个图像,形成画廊集用于模型性能的评估。我们随机分割画廊集并进行10次以上的评估,报告平均性能。
实验结果
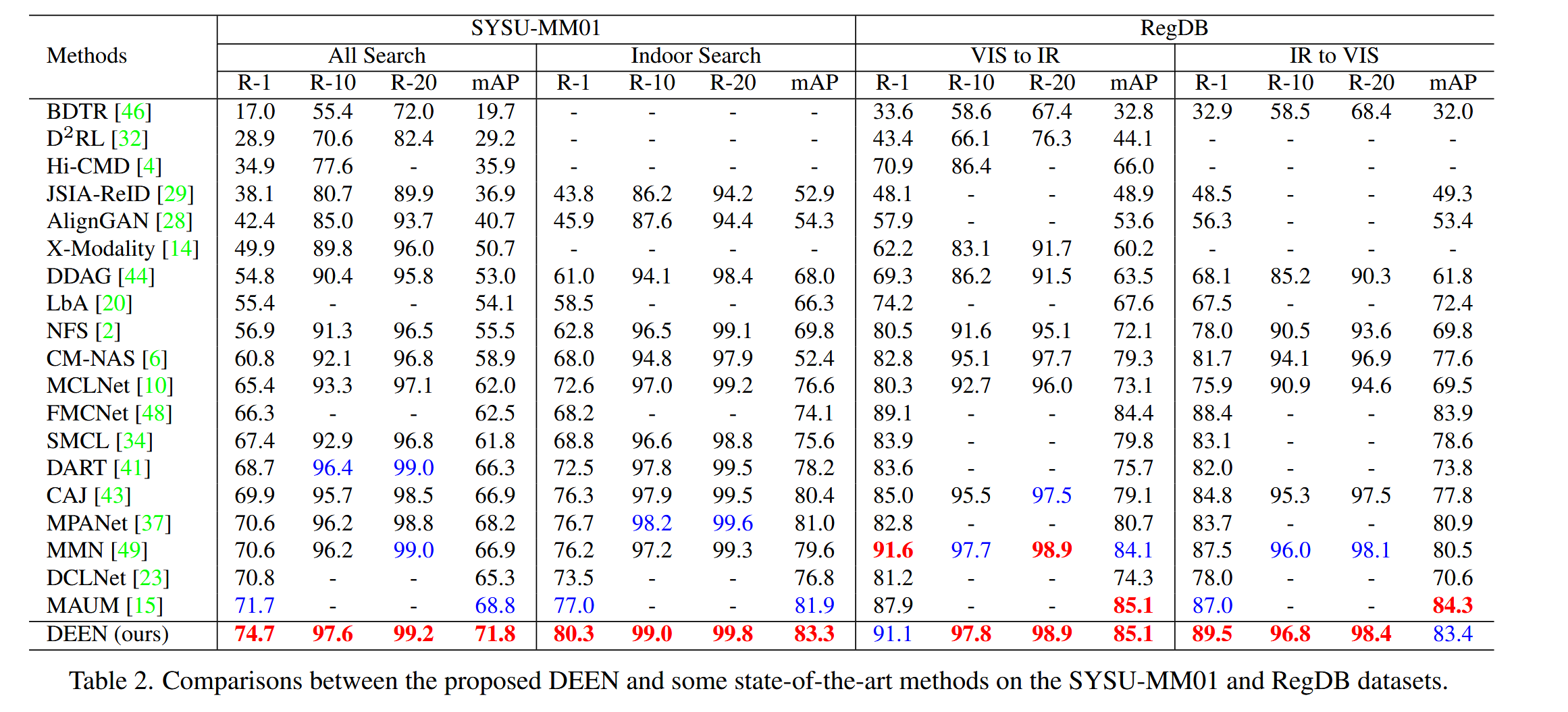
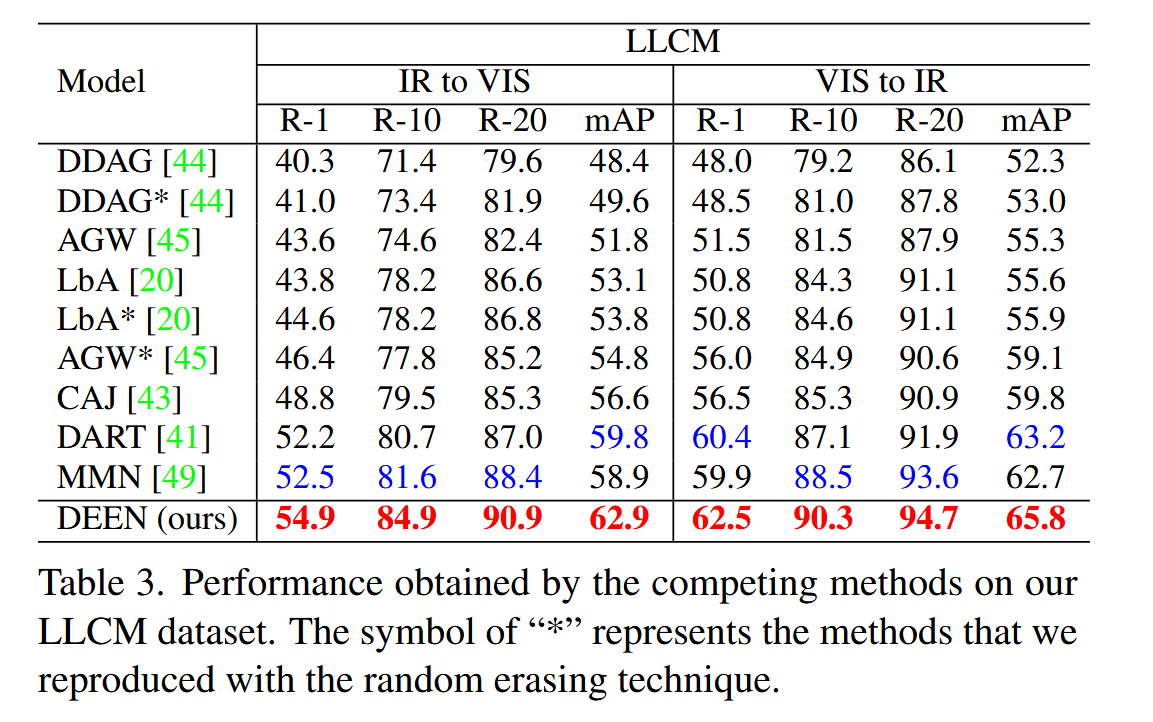
可以看到DEEN在三个数据集上相比之前的方法都取得了SOTA的效果
消融实验
各组件消融
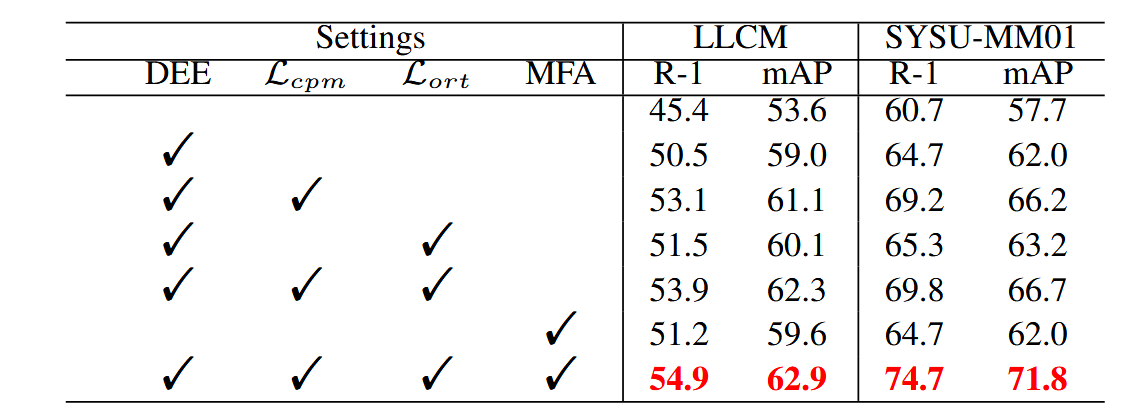
为了评估DEEN中各组件的贡献,进行了消融研究。结果显示,尽管DEE模块略微提升了基线性能,但效果有限。然而,结合CPM损失后,DEE显著提升了模型性能,并减少了VIS和IR图像之间的模态差异。此外,MFA模块通过聚合不同阶段的特征,进一步提高了性能。综合DEE、CPM和MFA的端到端学习框架在两个具有挑战性的VIRReID数据集上表现出显著的性能提升,表明这些模块能互相受益,生成多样化的嵌入。
DEE插入位置消融
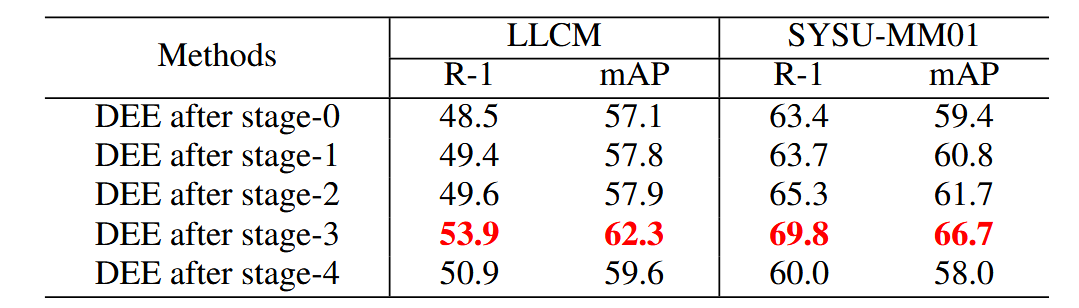
实验研究了在ResNet-50的不同阶段插入DEE模块对DEEN性能的影响。结果表明,当DEE模块插入在stage-0到stage-3之后时,性能逐步提高,说明模态差距减少,DEE在网络更深层的生成能力更强。在stage-3之后插入DEE在LLCM和SYSU-MM01数据集上达到了最佳效果。然而,在stage-4之后插入DEE时,性能显著下降,因为CPM损失直接作用于嵌入,增大了生成嵌入与原始嵌入之间的距离,增加了模型优化难度。因此,除非特别指定,我们默认将DEE插入在ResNet-50的stage-3之后。
DEE分支数消融
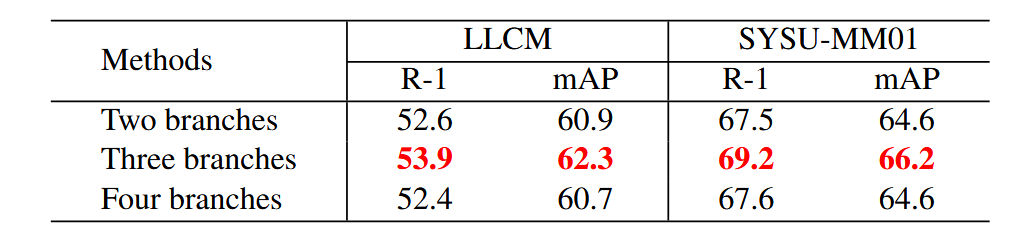
研究表明,DEE模块的性能随着分支数量从2增加到3而逐渐提高,因生成了更多的嵌入来减少模态差距。然而,当分支数量超过3时,性能因冗余特征过多而下降。因此,具有三个分支的DEE在LLCM和SYSU-MM01数据集上表现最佳,表明这是生成多样化嵌入的最佳配置。默认情况下,DEE模块使用三个分支。
MFA与NL对比消融
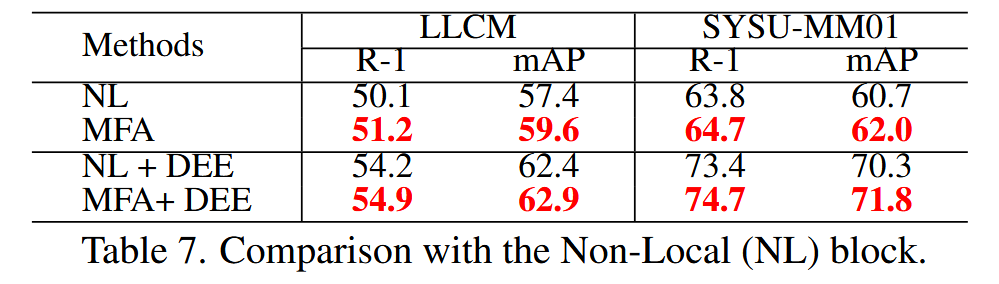
上表实验结果表明,MFA块比Non-Local块在Rank-1准确率和mAP上分别高出1.1%和2.2%,验证了MFA块的有效性。此外,MFA块和DEE模块在生成多样化嵌入、减少VIS和IR图像之间的模态差距方面相辅相成。
超参数消融
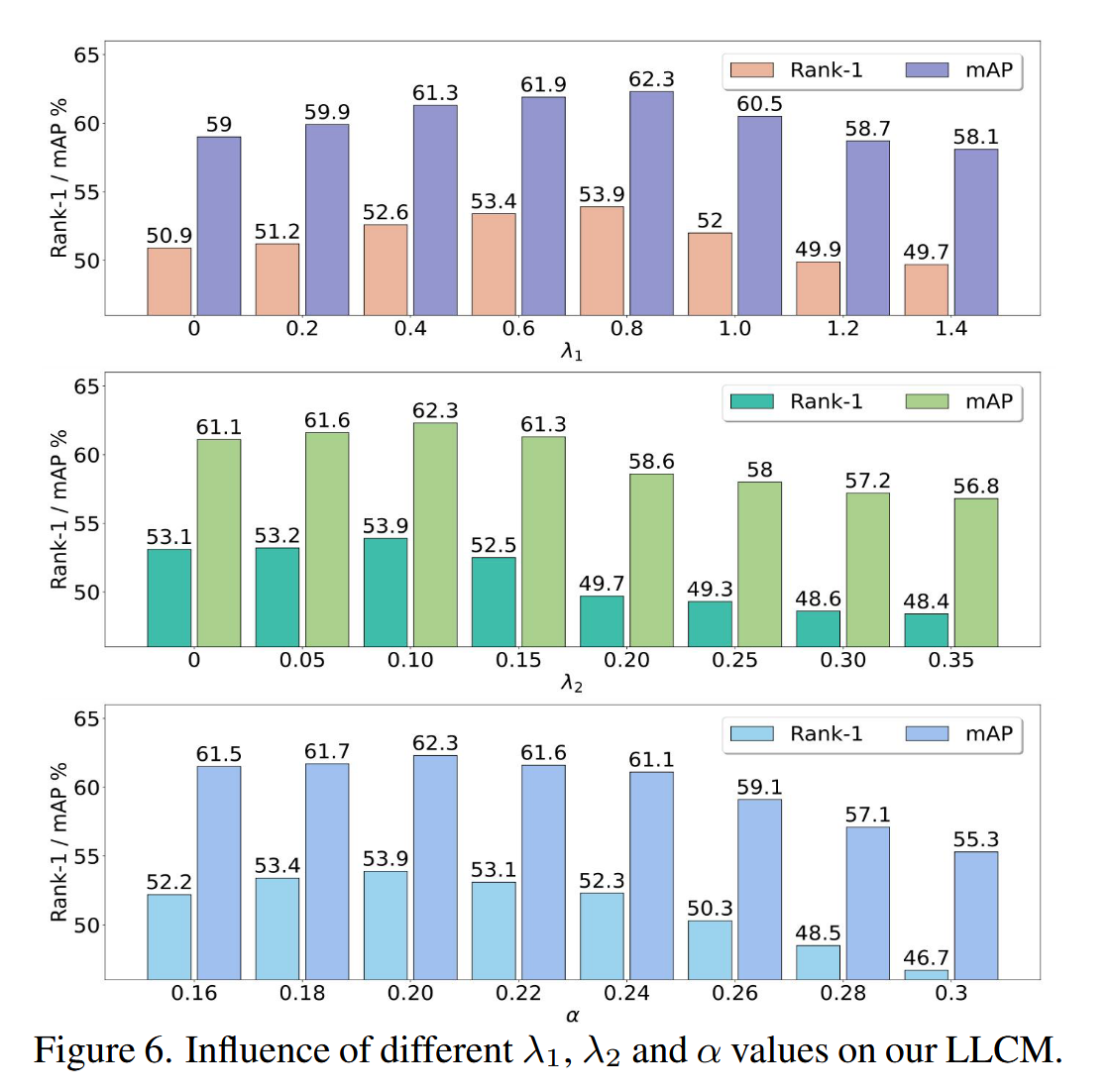
主要是对,和三个超参数进行消融实验,最后发现,,能够取得更好的实验结果。
可视化
特征分布
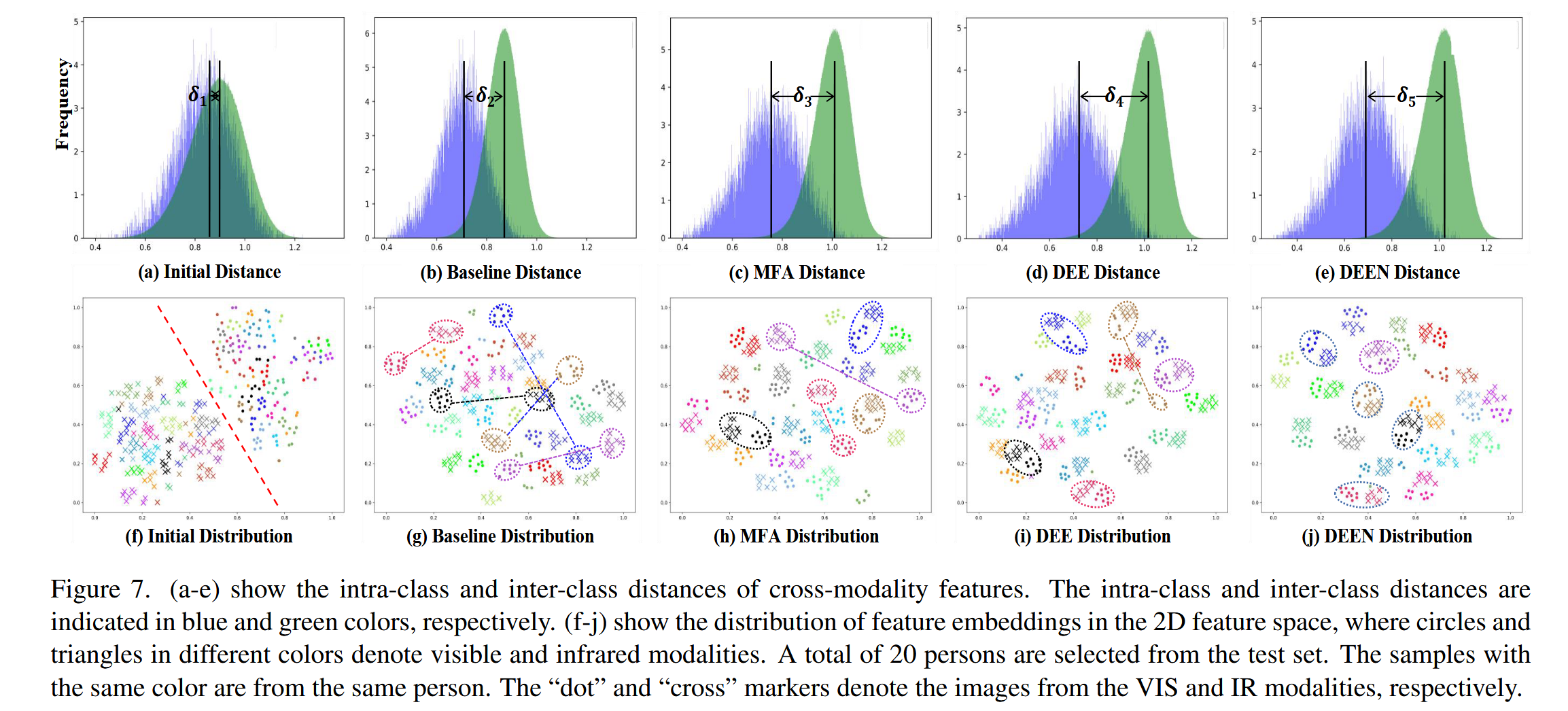
为了研究 DEEN 有效的原因,我们在 LLCM 数据集上可视化类间和类内距离,如上图 (a-e) 所示。比较上图(c-e)和上图(a-b),类间和类内距离的均值(即垂直线)被MFA、DEE和DEEN推开,其中δ1 <δ2 <δ3并且δ1<δ2<δ4<δ5。这表明,与初始特征(图7(a))和基线特征(图7(b))的类内距离相比,DEEN的类内距离显着减小。因此,DEEN可以有效地减少可见光和红外图像之间的模态差异。同时,我们还在上图(f-j)中用t-SNE可视化2D特征空间中的特征分布,这表明MFA、DEE和DEEN可以有效地区分和聚合同一个人的特征嵌入,并减少模态差异。
检索结果

为了进一步显示 DEEN 的有效性,为了进一步展示DEEN的有效性,我们在图8中展示了DEEN在我们的LLCM数据集上的一些检索结果。对于每个检索案例,绿色框表示与给定查询对应的正确匹配图像,而红色框表示不正确的匹配图像。总体而言,与基线相比,DEEN可以有效地改进排序结果,使更多正确匹配的图像排在前面的位置。
总结
在本文中,我们提出了一种新颖的多样化嵌入扩展网络(DEEN),用于VIRelD任务的嵌入空间。所提出的DEEN可以生成多样化的嵌入,并挖掘多样的通道级和空间嵌入,以学习信息丰富的特征表示,从而减少VIS和IR图像之间的模态差异。此外,我们还提供了一个具有挑战性的低光跨模态(LLCM)数据集,该数据集包含更多新的重要特征,可以进一步促进VIRelD研究向实际应用迈进。对SYSU-MM01、RegDB和LLCM数据集的广泛实验表明,所提出的DEEN在多种最新方法中具有优越性。