文章基本信息
- 文章名称:Adaptive Uncertainty-Based Learning for Text-Based Person Retrieval
- 发表会议/年份:AAAI 2024
- 作者:Shenshen Li, Chen He, Xing Xu*, Fumin Shen, Yang Yang, Heng Tao Shen
- 单位:School of Computer Science and Engineering and Center for Future Media, University of Electronic Science and Technology of China, China
摘要
基于文本的行人检索旨在根据文本描述从图库中检索特定的行人图像。主要挑战是如何在显著的类内变化和最小的类间变化情况下克服固有的异质模态差距。现有的方法通常采用视觉-语言预训练或注意力机制,从噪声输入中学习适当的跨模态对齐。尽管取得了显著进展,当前的方法不可避免地存在两个缺陷:1) 匹配歧义,主要源于不可靠的匹配对;2) 单方面的跨模态对齐,源于缺乏探索一对多对应关系,即粗粒度语义对齐。这些关键问题显著降低了检索性能。为此,我们提出了一种新颖的框架,称为基于自适应不确定性的学习(Adaptive Uncertainty-Based Learning,AUL),用于从不确定性角度进行基于文本的行人检索。具体来说,我们的AUL框架由三个关键组件组成:1) 不确定性感知匹配过滤,利用主观逻辑(Subjective Logic) 有效减少不可靠匹配对的干扰,并选择高置信度的跨模态匹配进行训练;2) 基于不确定性的对齐优化,不仅通过构建不确定性表示来模拟粗粒度对齐,还进行渐进学习,以适当地结合粗粒度和细粒度对齐;3) 跨模态掩码建模,旨在探索视觉和语言之间更全面的关系。大量实验表明,我们的AUL方法在监督、弱监督和域泛化设置下的三个基准数据集上始终实现了最先进的性能。我们的代码可在 https://github.com/CFM-MSG/Code-AUL 获取。
之前工作存在的问题
- 匹配模糊性:由于仅考虑一对一匹配,忽略了语言和视觉之间的一对多对应关系,导致匹配模糊,限制了模型的性能和泛化能力。
- 单方面的跨模态对齐:这些方法往往无法全面捕捉视觉和语言之间的关系,导致对齐过程单方面且不完整。
- 不可靠的匹配对:由于类内变化大和类间变化小引入的固有数据噪声,基于相似性选择的跨模态匹配对往往不准确,可能会错误地将负样本识别为真实标签,进一步降低了匹配的准确性。
主要贡献/创新
基于上述观察,提出了一种名为自适应不确定性学习(AUL,Adaptive Uncertainty-based Learning)的新框架,用于从不确定性角度进行基于文本的人员检索。我们的主要贡献可以总结如下:
-
不确定性感知匹配过滤策略:通过仔细考虑匹配不确定性,我们设计了一种不确定性感知匹配过滤(Uncertainty-aware Matching Filtration)策略,该策略利用主观逻辑(Subjective Logic)自适应地选择高置信度的跨模态匹配,减轻不可靠匹配对对训练的干扰。
-
基于不确定性的对齐优化模块:我们提出了一个基于不确定性的对齐优化(Uncertainty-based Alignment Refinement)模块,该模块不仅通过构建不确定性表示来模拟粗粒度对齐,还逐步组织多粒度对齐。
-
跨模态掩码建模模块:我们部署了一个跨模态掩码建模(Cross-modal Masked Modeling)模块,通过全面的跨模态交互重构图像和文本模态信号,进一步探索两种模态之间的对应关系。
方法
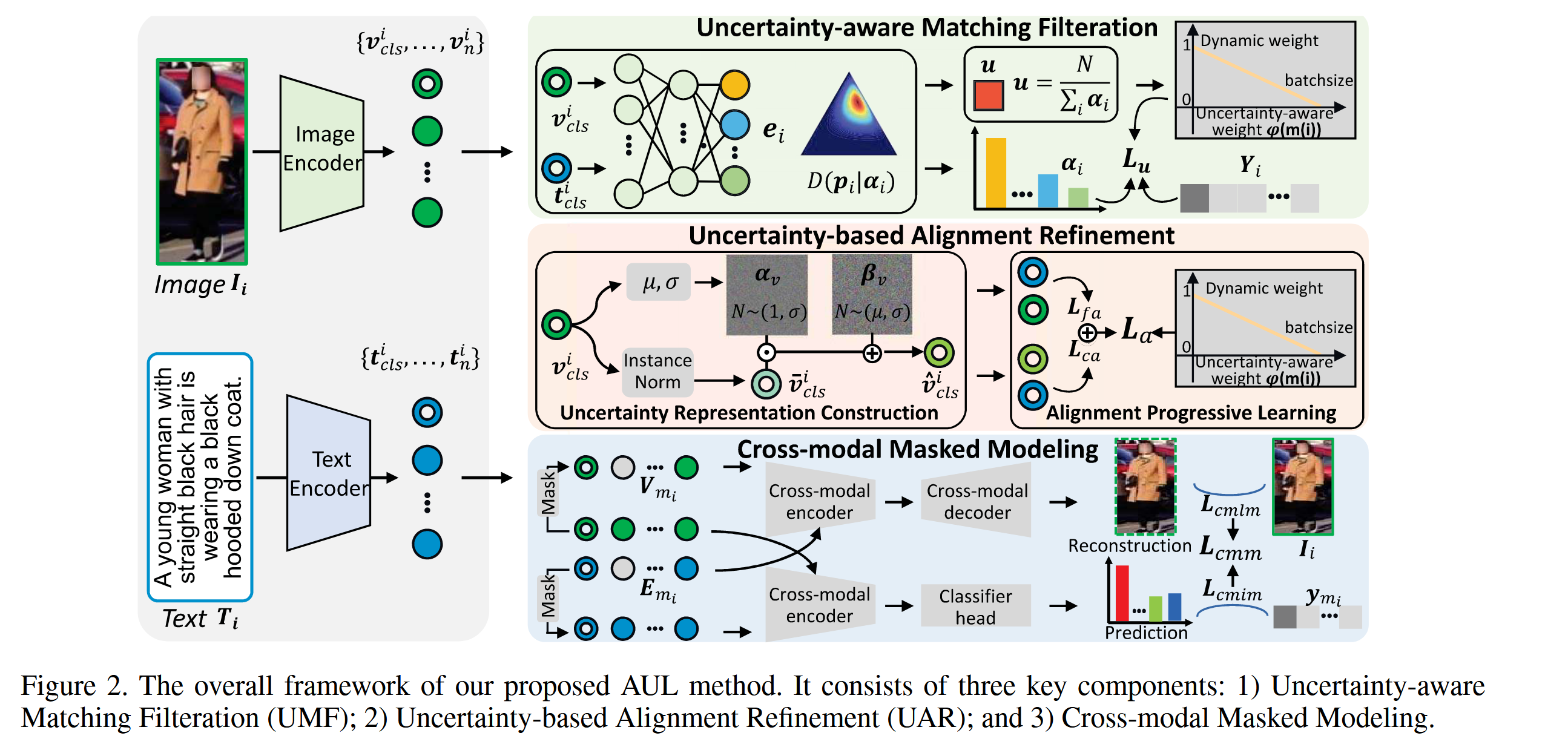
Preliminary
基于文本的人员检索任务的目标是从候选库中分辨并检索到与提供的文本查询最匹配的人员图像。为了获取正确的行人图像,我们提出的框架侧重于通过学习文本描述与对应人员图像之间的相似性来促进精确的对齐。
形式上,我们定义为训练数据集中的图像-文本对。每对包括一张人员图像及其对应的文本描述。我们首先将图像输入到图像编码器中,生成一系列视觉特征,其中作为全局视觉特征,表示视觉补丁特征。此外,我们利用文本编码器获得一系列文本表示,其中和分别表示全局文本特征和标记特征。
Uncertainty-aware Matching Filtration(UMF)
模块目的: 使用主观逻辑对文本图像对匹配的不确定性进行建模,用于筛选可靠匹配,减轻由于不可靠匹配对 带来的不确定性影响
主观逻辑背景
主观逻辑(Subjective Logic,SL)提供了对Dempster-Shafer理论(Yager 和 Liu 2008)不确定性分配原则的形式化表示,建模为狄利克雷分布。因此,它提供了利用SL理论量化不确定性的方法,在严格建立的理论框架内进行。具体来说,我们首先获得针对第个单元预测的证据向量。然后我们为每个单元建模不确定性和信任质量,其公式如下:
其中,可以被认为是狄利克雷分布的强度,而信任概率对应于狄利克雷分布的参数。注意,不确定性与总证据呈反比关系。最后,由描述的狄利克雷分布可以定义为:
其中表示N维贝塔函数,是N维单纯形。
不确定性感知学习
为了有效减轻由于不可靠匹配对带来的不确定性影响,需要对匹配不确定性进行建模。尽管主观逻辑(Subjective Logic, SL)理论在不确定性建模方面显示了显著的进展,但直接将其应用于基于文本的人员检索并不合适。为了将SL扩展到这一特定任务,初步步骤是表示第个文本与第个图像之间的跨模态匹配证据,其中和分别表示余弦相似度和ReLU函数。第个文本的所有匹配的总证据可以表示为。
根据前一部分提到的主观逻辑,我们获得了并将匹配不确定性建模如下:
其中,可以被视为狄利克雷分布的强度。基于获得的匹配不确定性,我们执行不确定性感知学习,自适应地过滤不可靠的匹配对并选择高置信度的跨模态匹配。具体来说,我们设计了具有不确定性感知动态权重函数的交叉熵损失,在优化过程中为具有较低匹配不确定性的跨模态匹配分配较大的权重,为具有较高匹配不确定性的匹配分配较小的权重,从而减少由不可靠匹配对造成的负面影响。损失函数可以表示为:
其中,是超参数,是第个样本的one-hot标签,,表示通过按降序排列不确定性获得的第个跨模态匹配的序号。
模块亮点:不同于之前ReID问题所采用的triplet等损失函数,他是一个比较软的约束条件,triplet等函数从标签判定,标签不一致,直接权重就是0,这里通过相似度计算的不确定性进行约束,或许能让模型拥有更强的泛化性能
Uncertainty-based Alignment Refinement
模块目的: Uncertainty-based Alignment Refinement(UAR)模块旨在解决视觉和语言之间缺乏一对多对应关系的问题,导致检索性能退化。通过构建具有不确定性的视觉表示,并采用渐进学习方法,UAR 模块在训练过程中逐步优化粗粒度和细粒度对齐,最终提高跨模态检索性能。
由于视觉和语言之间缺乏一对多的对应关系,现有方法主要集中于探索单方面的跨模态对齐,即一对一的对应关系,导致检索性能退化。为了解决这一限制,我们提出了基于不确定性的对齐优化(Uncertainty-based Alignment Refinement,UAR)模块,该模块模拟粗粒度对齐,并采用渐进学习以易到难的方式协同优化粗粒度和细粒度对齐。
不确定性表示构建:鉴于个图像-文本对的全局表示,我们首先需要显式构建具有不确定性的视觉表示,这通过将高斯噪声添加到原始特征分布中来实现。高斯噪声的均值和标准差从原始特征中得出。然后我们通过将生成的高斯噪声添加到归一化后的特征来构建具有不确定性的视觉表示,其公式如下:
其中,和是引入噪声的不确定性向量,,,是归一化后的特征:
渐进对齐学习:基于获得的不确定性视觉表示和文本表示,我们采用InfoNCE损失(InfoNCE loss)(Lee, Kim, and Han 2021;Yang et al. 2023)进行粗粒度对齐,并进一步探索一对多对应关系。粗粒度对齐损失可以定义为:
对于细粒度对齐,即一对一对应关系,我们设计了一种成对损失函数以缓解密集采样机制的负面影响(Zhou et al. 2023)。成对损失函数使用一个负样本写为:
直观上,进行细粒度对齐比粗粒度对齐更具挑战性。因此,我们的策略是在训练过程中逐步为粗粒度对齐分配较高的权重,而为细粒度对齐分配较低的权重,最终逐步逆转这种分配。我们提出了对齐渐进学习(Alignment Progressive Learning,APL),将动态权重引入损失函数,使其逐步关注多粒度对齐,并在优化过程中按“易到难”的方式逐步优化目标,如下所示:
其中,,是初始权重。
Cross-modal Masked Modeling
模块目的: 受MAE的启发,通过自监督学习提升模型的性能,增加两种模态的交互,消除模态差异造成的影响
为了增强图像和文本之间的交互,我们设计了跨模态掩码建模(Cross-modal Masked Modeling,CMM),通过使用掩码输入来重构一种模态的内在信号,该输入依赖于图像和文本模态的未掩码输入。CMM可以进一步分为两个部分:跨模态掩码图像建模(Cross-modal Masked Image Modeling,CMIM)和跨模态掩码语言建模(Cross-modal Masked Language Modeling,CMLM)。
以CMIM为例,按照MAE(He等,2022)的方式,我们获得掩码图像的表示,其中表示未掩码标记的数量。然后,我们利用包括多头交叉注意力层和三层变换器块的跨模态编码器,根据掩码图像和原始文本表示的表示,预测所有原始标记。最后,通过图像跨模态解码器将预测结果映射回RGB图像空间,解码器的结构与编码器相同,后接一个线性层。CMIM的总过程表示为:
其中,表示像素的数量,损失函数基于损失。
类似于CMIM,给定掩码文本表示和原始视觉表示,我们利用交叉熵损失函数来测量预测与掩码文本标记之间的距离,即进行跨模态掩码语言建模。CMM的目标可以计算为:
其中,是第个掩码标记的one-hot标签,与CMIM的跨模态编码器相同,是分类器头。通过最小化,模型被迫通过跨模态交互执行原始信号的重构。此过程有效促进了图像和文本模态之间更深层次关系的探索。
最终,训练的总损失表示为:
实验结果
消融实验
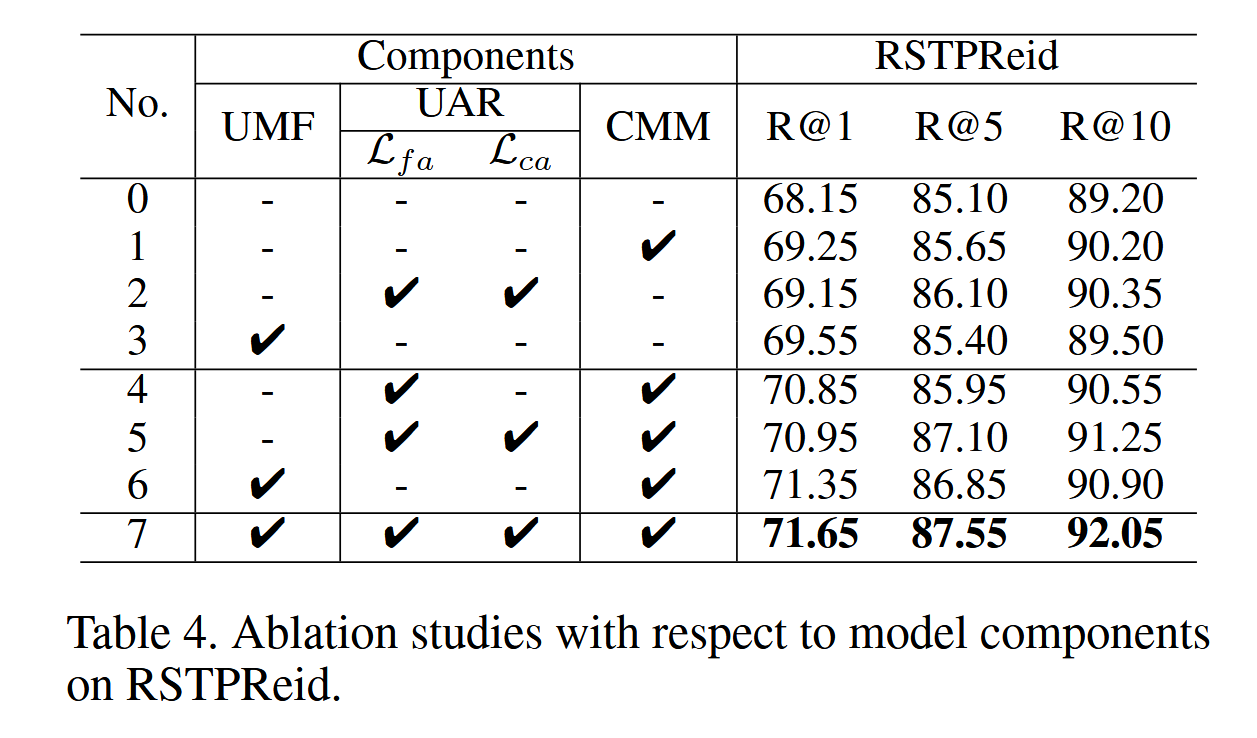
如表4所示,我们得出以下结论:
- 对比No.0和No.3,表明我们提出的不确定性感知匹配过滤(UMF)显著提升了检索性能。这再次证明,引入主观逻辑(SL)理论来建模跨模态匹配模糊的不确定性对于筛选高置信度对齐是有效的,使我们的模型能够专注于可靠的检索结果。
- No.5的模型性能优于No.1,特别是在R@5和R@10方面。这表明基于不确定性的对齐优化(UAR)通过应用基于高斯噪声的不确定性表示可以有效地探索一对多的对应关系。此外,UAR采用的渐进学习方法能够适当地结合粗粒度和细粒度对齐。
- 从No.6和No.3的比较中,我们推测添加跨模态掩码建模(CMM)对检索性能有更大的影响。一个可能的原因是,通过进一步的跨模态交互进行掩码语言建模(MLM)和掩码图像建模(MIM),在视觉和语言之间的细粒度和相关关系挖掘方面带来了额外的优势。
关于选择CMLM还是CMIM的分析
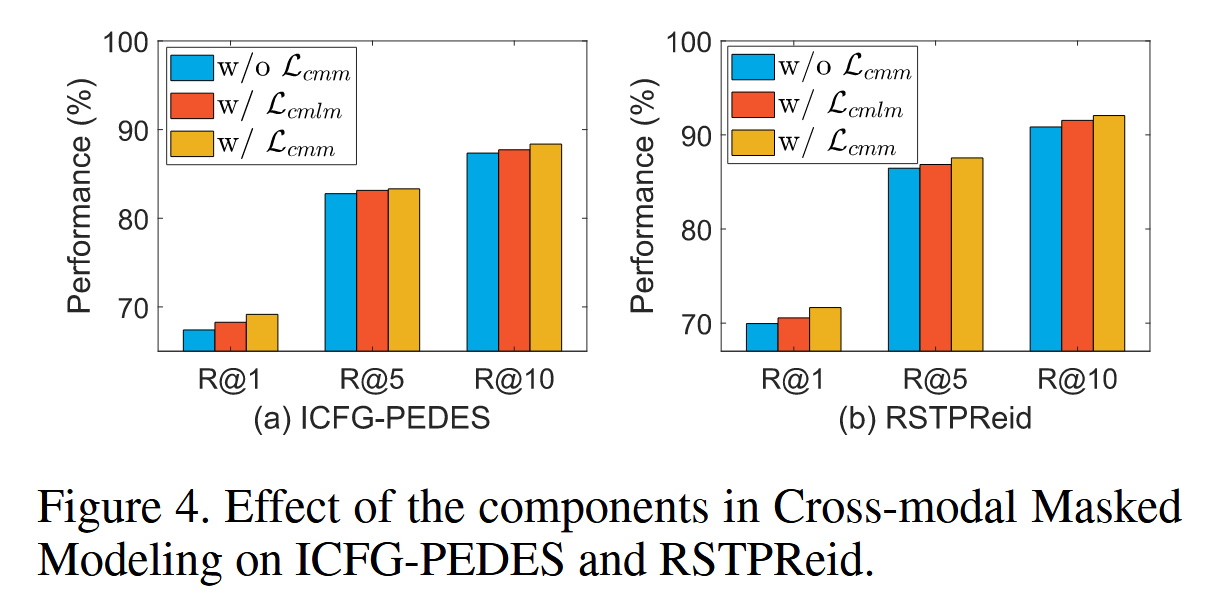
对CMLM和CMIM选择的分析。我们进一步探讨了CMLM和CMIM各自的重要性。如图4所示,我们可以观察到:
-
含有的消融模型(w/)表现优于基线模型。我们认为,性能提升的原因在于图像和文本之间的充分交互,这有助于弥合视觉和语言之间显著的模态差距。
-
然而,仅应用CMLM的损失并不如同时应用CMIM和CMLM(即w/ CMM)的组合效果好。这表明,将掩码文本和视觉标记同时作为挖掘全面跨模态关系的锚点是不可或缺的。
对UAR中渐进对齐学习APL的分析
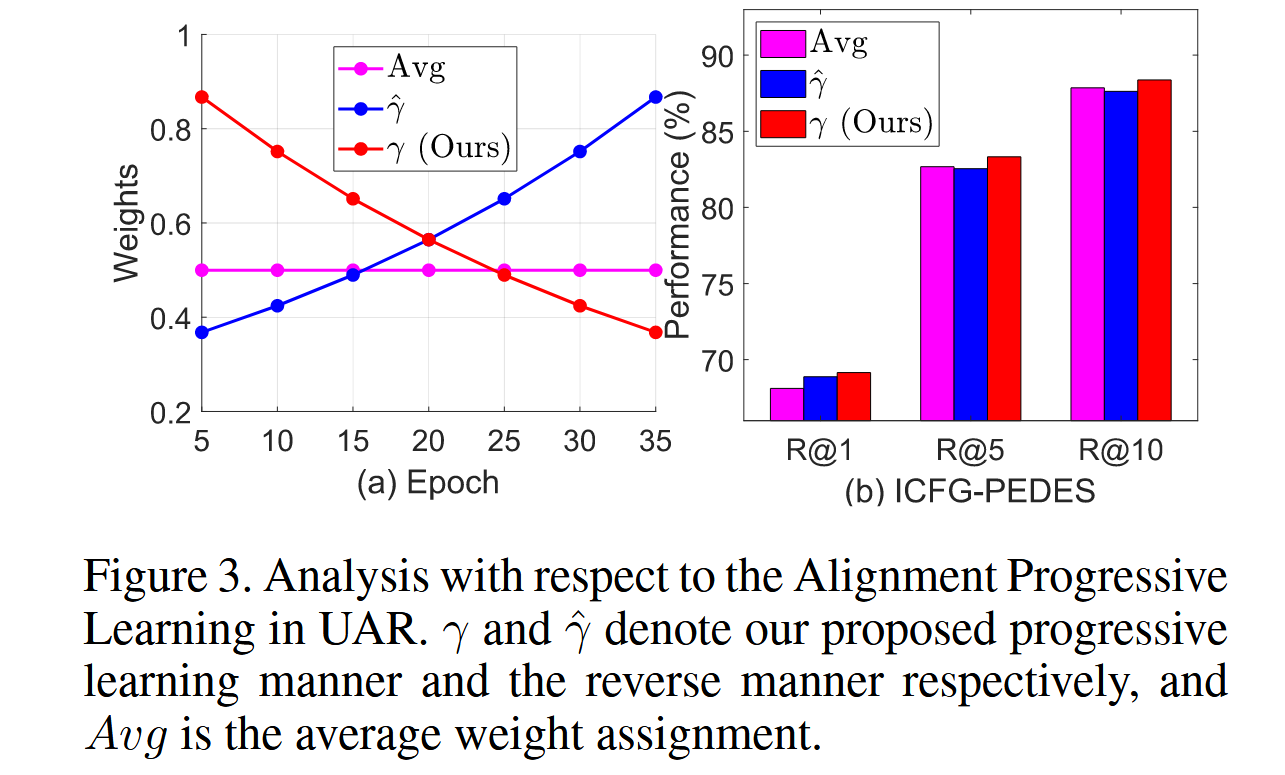
在此,我们研究了我们提出的渐进对齐学习(Alignment Progressive Learning,APL)的进展,APL旨在全面探索一对一和一对多的对应关系。通过观察图3,我们可以发现:
-
引入动态权重(\gamma)的效果优于使用平均权重的消融模型(Avg)。我们推测其原因是渐进学习的应用在学习全面的多粒度对齐中起到了重要作用。
-
所提出的APL初始阶段有效地为粗粒度对齐分配了较高的权重,并逐步转向为细粒度对齐分配更高的权重。
-
此外,我们进一步探索了以易到难的方式学习多粒度对齐的有效性。特别地,我们比较了利用(\gamma)和(\hat{\gamma})的性能。显然,前者在适当的对齐整合和检索准确性方面表现出更好的适应性。这一发现支持我们的直觉,即引导模型以易到难的方式逐步学习适当的多粒度对齐是比其他方法更合理的。
对匹配不确定性感知动态权重分配的分析
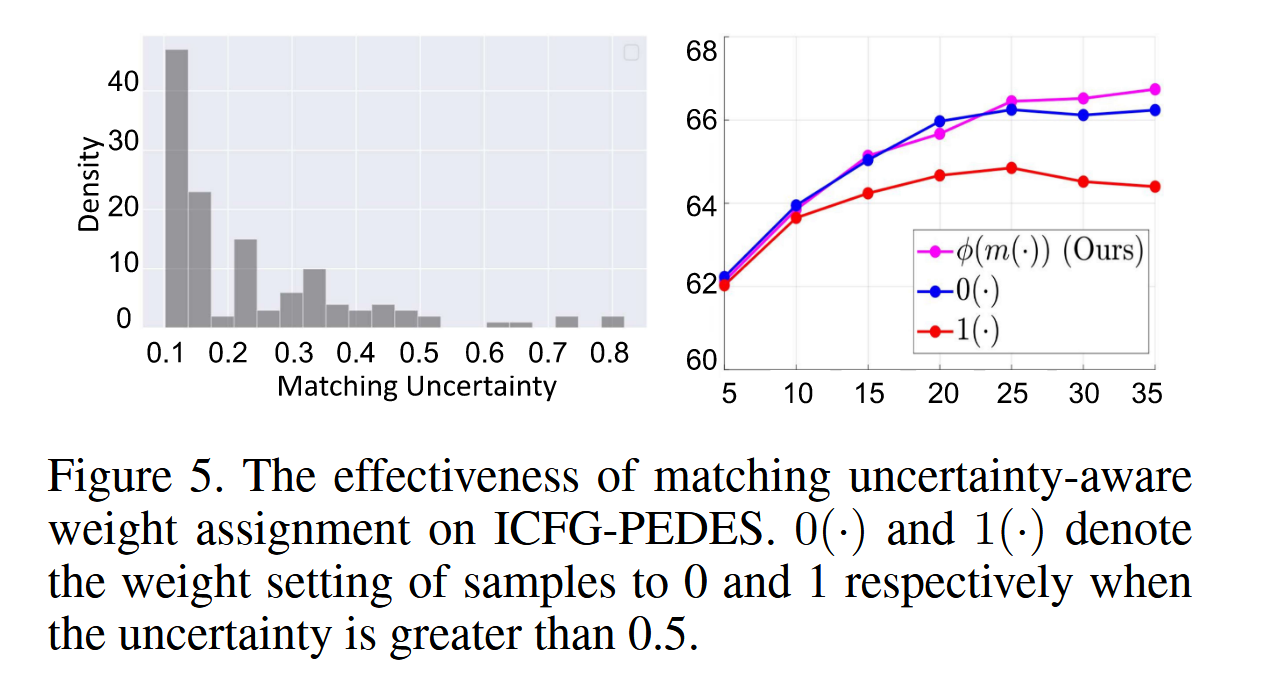
为了进一步验证匹配模糊性的存在及我们提出的UMF的重要性,我们深入研究了各种不确定性感知权重分配与整体性能之间的关系。从图5中得出的观察结果如下:
- 分布分析清楚地揭示了不可靠匹配对的存在,这些对特征为显著的匹配不确定性。这种不确定性源于显著的类内变化和有限的类间变化,阻碍了检索性能的提升。
- 为了强调匹配不确定性感知动态权重分配的有效性,我们比较了不同权重分配的性能。将高不确定性的跨模态匹配设为1(⋅)的性能最差,这反映了我们的模型受严重匹配模糊性影响这一动机的合理性。
Qualitative Analysis

如图6所示,我们进行了定性分析,比较了我们提出的AUL方法与近期的APTM方法(Yang等,2023)在前6个检索结果中的表现。根据可视化结果,我们的AUL方法在检索准确性上优于APTM方法。具体来说,我们的方法AUL能够满足细粒度和粗粒度的检索需求,例如“长袖”或“高个子男人”,因为我们提出的UAR能够逐步且全面地获取多粒度语义。此外,AUL还对匹配不确定性进行建模,以量化由类内变化大和类间变化小引起的模糊性,从而减轻不可靠匹配对的干扰,提高性能。
总结
在本文中,我们提出了一种新颖的自适应不确定性学习(Adaptive Uncertainty-based Learning,AUL)方法,从不确定性角度出发进行基于文本的人员检索。我们提出了不确定性感知匹配过滤(Uncertainty-aware Matching Filtration,UMF)来量化并防止由于不可靠匹配对引起的模糊影响。此外,我们设计了基于不确定性的对齐优化(Uncertainty-based Alignment Refinement,UAR)和跨模态掩码建模(Cross-modal Masked Modeling,CMM)来增强对齐学习并关注适当的跨模态关系。在三个基准上的大量实验表明了我们提出的AUL方法的优越性。未来,我们将探索其他策略以进一步提升检索性能。