文章基本信息
文章名称:Denoising Diffusion Probabilistic Models
发表会议/年份:NeurIPS 2020
作者:Jonathan Ho, Ajay Jain, Pieter Abbeel
单位:UC Berkeley
前置知识
Markov:当前位置的概率只会受到前一时刻概率影响
正态分布的叠加性e g . N ( μ 1 , σ 1 2 ) + N ( μ 2 , σ 2 2 ) = N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) eg. N(\mu_1,\sigma_1^2)+N(\mu_2,\sigma_2^2) = N(\mu_1+\mu_2,\sigma_1^2+\sigma_2^2) e g . N ( μ 1 , σ 1 2 ) + N ( μ 2 , σ 2 2 ) = N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 )
贝叶斯:P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B) = \frac{P(B|A)P(A)}{P(B)} P ( A ∣ B ) = P ( B ) P ( B ∣ A ) P ( A ) P ( A ∣ B , C ) = P ( B ∣ A , C ) P ( A ∣ C ) P ( B ∣ C ) P(A|B,C) = \frac{P(B|A,C)P(A|C)}{P(B|C)} P ( A ∣ B , C ) = P ( B ∣ C ) P ( B ∣ A , C ) P ( A ∣ C )
开始推理
前向过程
我们定义每次加入的噪声是一个正态分布,满足如下式子:
q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , β t I ) q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t} x_{t-1}, \beta_t I)
q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , β t I )
在DDPM(Denoising Diffusion Probabilistic Models)中,这个公式表示从时间步骤 t − 1 t-1 t − 1 t t t 转移概率 。具体来说,q ( x t ∣ x t − 1 ) q(x_t | x_{t-1}) q ( x t ∣ x t − 1 ) x t − 1 x_{t-1} x t − 1 x t x_t x t
符号 N \mathcal{N} N α t x t − 1 \sqrt{\alpha_t} x_{t-1} α t x t − 1 β t I \beta_t I β t I α t \alpha_t α t β t \beta_t β t t t t I I I
在DDPM中,这个过程通常被用来逐步增加数据的噪声,其中 α t \alpha_t α t β t \beta_t β t
x t = α t x t − 1 + β t ϵ t ϵ t ∼ N ( 0 , I ) x_t = \sqrt{\alpha_t} x_{t-1} + \sqrt{\beta_t}\epsilon_t \quad \epsilon_t \sim \mathcal{N}(0, I)
x t = α t x t − 1 + β t ϵ t ϵ t ∼ N ( 0 , I )
α t = 1 − β t \alpha_t = 1-\beta_t
α t = 1 − β t
我们可以将递归式展开,变为直接O ( 1 ) O(1) O ( 1 )
x t = α t x t − 1 + β t ϵ t = α t ( α t − 1 x t − 2 + β t − 1 ϵ t − 1 ) + β t ϵ t = ⋯ = ( α t ⋯ α 1 ) x 0 + ( α t ⋯ α 2 ) β 1 ϵ 1 + ( α t ⋯ α 3 ) β 2 ϵ 2 + ⋯ + α t β t − 1 ϵ t − 1 + β t ϵ t ⏟ N ( 0 , ( 1 − α t 2 ⋯ α 2 2 ) I ) \begin{align*}
x_t &= \alpha_t x_{t-1} + \beta_t \epsilon_t \\
&= \alpha_t (\alpha_{t-1}x_{t-2} + \beta_{t-1}\epsilon_{t-1}) + \beta_t \epsilon_t \\
&= \cdots \\
&= (\alpha_t \cdots \alpha_1)x_0 + \underbrace{(\alpha_t \cdots \alpha_2)\beta_1\epsilon_1 + (\alpha_t \cdots \alpha_3)\beta_2\epsilon_2 + \cdots + \alpha_t \beta_{t-1}\epsilon_{t-1} + \beta_t \epsilon_t}_{\mathcal{N}(0, (1-\alpha_t^2 \cdots \alpha_2^2)I)}
\end{align*}
x t = α t x t − 1 + β t ϵ t = α t ( α t − 1 x t − 2 + β t − 1 ϵ t − 1 ) + β t ϵ t = ⋯ = ( α t ⋯ α 1 ) x 0 + N ( 0 , ( 1 − α t 2 ⋯ α 2 2 ) I ) ( α t ⋯ α 2 ) β 1 ϵ 1 + ( α t ⋯ α 3 ) β 2 ϵ 2 + ⋯ + α t β t − 1 ϵ t − 1 + β t ϵ t
我们设:α ‾ t = α 1 ⋯ α t \overline{\alpha}_t=\alpha_1\cdots \alpha_t α t = α 1 ⋯ α t
化简上式可得:
q ( x t ∣ x 0 ) = α ‾ t x 0 + 1 − α ‾ t ϵ ϵ ∼ N ( 0 , I ) q(x_t|x_0) = \sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}\epsilon\quad\epsilon\sim\mathcal{N}(0,I)
q ( x t ∣ x 0 ) = α t x 0 + 1 − α t ϵ ϵ ∼ N ( 0 , I )
q ( x t ∣ x 0 ) = N ( x t ; α ‾ t x 0 , ( 1 − α ‾ t ) I ) q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\overline\alpha_t} x_0, (1 - \overline\alpha_t)I)
q ( x t ∣ x 0 ) = N ( x t ; α t x 0 , ( 1 − α t ) I )
这里 ϵ \epsilon ϵ N ( 0 , 1 ) \mathcal{N}(0, 1) N ( 0 , 1 )
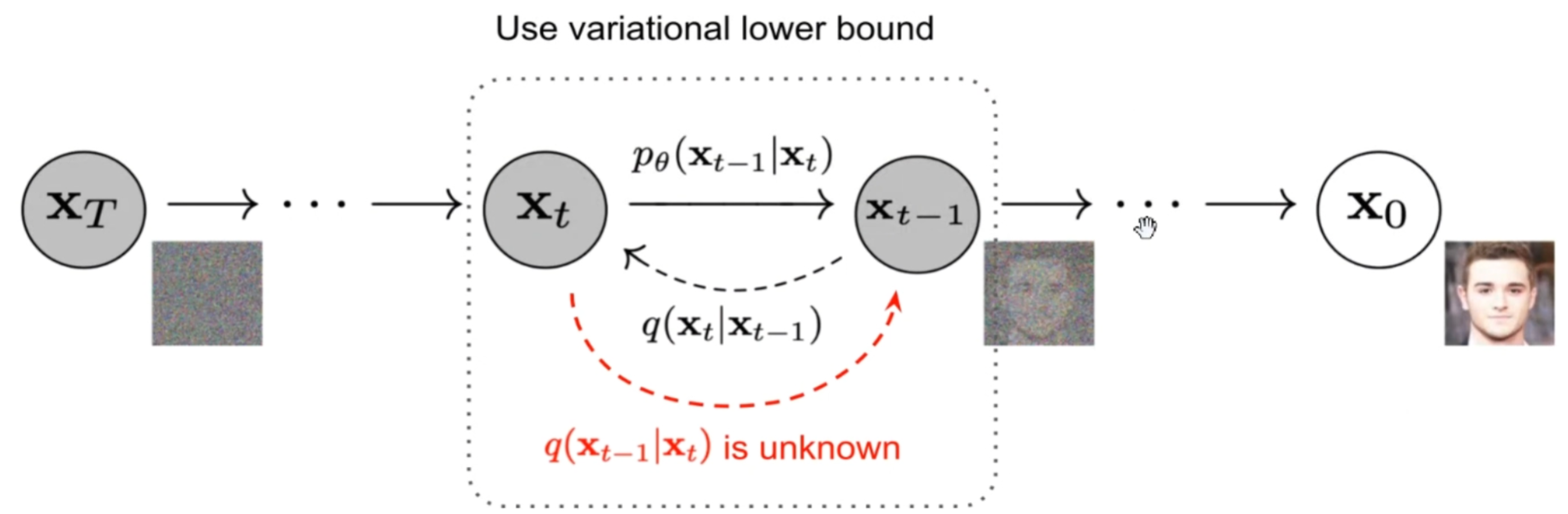
逆向过程
逆向过程又称去噪过程,之前的前向过程是给定x 0 x_0 x 0 x t x_t x t q ( x t ∣ x 0 ) q(x_t|x_0) q ( x t ∣ x 0 ) x t x_t x t x 0 x_0 x 0 p ( x 0 ∣ x t ) p(x_0|x_t) p ( x 0 ∣ x t )
p ( x 0 ∣ x t ) = p ( x 0 ∣ x 1 ) p ( x 1 ∣ x 2 ) ⋯ p ( x t − 1 ∣ x t ) = ∏ i = 0 t − 1 p ( x i ∣ x i + 1 ) p(x_0 | x_t) = p(x_0 | x_1)p(x_1 | x_2) \cdots p(x_{t-1} | x_t) = \prod_{i=0}^{t-1} p(x_i | x_{i+1})
p ( x 0 ∣ x t ) = p ( x 0 ∣ x 1 ) p ( x 1 ∣ x 2 ) ⋯ p ( x t − 1 ∣ x t ) = i = 0 ∏ t − 1 p ( x i ∣ x i + 1 )
那如何求解p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q ( x t ∣ x t − 1 )
p ( x t − 1 ∣ x t ) = p ( x t ∣ x t − 1 ) p ( x t − 1 ) p ( x t ) p(x_{t-1}|x_t) = \frac{p(x_t|x_{t-1})p(x_{t-1})}{p(x_t)}
p ( x t − 1 ∣ x t ) = p ( x t ) p ( x t ∣ x t − 1 ) p ( x t − 1 )
注意:这里的(去噪)p和上面的(加噪)q只是对分布的一种符号记法,它们是等价的.
然后就又有一个新的问题,p ( x t − 1 ) p(x_{t-1}) p ( x t − 1 ) p ( x t ) p(x_t) p ( x t ) p ( x t − 1 ∣ x 0 ) p(x_{t-1}|x_0) p ( x t − 1 ∣ x 0 ) p ( x t ∣ x 0 ) p(x_t|x_0) p ( x t ∣ x 0 )
p ( x t − 1 ∣ x t , x 0 ) = p ( x t ∣ x t − 1 , x 0 ) p ( x t − 1 ∣ x 0 ) p ( x t ∣ x 0 ) p(x_{t-1} | x_t, x_0) = \frac{p(x_t | x_{t-1}, x_0) p(x_{t-1} | x_0)}{p(x_t | x_0)}
p ( x t − 1 ∣ x t , x 0 ) = p ( x t ∣ x 0 ) p ( x t ∣ x t − 1 , x 0 ) p ( x t − 1 ∣ x 0 )
因为我们定义了DDPM是一个markov过程 ,所以上式中的p ( x t ∣ x t − 1 , x 0 ) p(x_t|x_{t-1},x_0) p ( x t ∣ x t − 1 , x 0 ) p ( x t ∣ x t − 1 ) p(x_t|x_{t-1}) p ( x t ∣ x t − 1 )
p ( x t − 1 ∣ x t , x 0 ) = p ( x t ∣ x t − 1 ) p ( x t − 1 ∣ x 0 ) p ( x t ∣ x 0 ) p(x_{t-1}|x_t,x_0) = \frac{p(x_t|x_{t-1})p(x_{t-1}|x_0)}{p(x_t|x_0)}
p ( x t − 1 ∣ x t , x 0 ) = p ( x t ∣ x 0 ) p ( x t ∣ x t − 1 ) p ( x t − 1 ∣ x 0 )
OK, 然后下面我们来整理一下右侧式子中的每个p的表达式,看看左侧p p p
首先是p ( x t − 1 ∣ x 0 ) p(x_{t-1}|x_0) p ( x t − 1 ∣ x 0 ) p ( x t ∣ x 0 ) p(x_t|x_0) p ( x t ∣ x 0 )
p ( x t − 1 ∣ x 0 ) = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ ∼ N ( α ˉ t − 1 x 0 , 1 − α ˉ t − 1 ) p(x_{t-1}|x_0) = \sqrt{\bar\alpha_{t-1}}x_0+\sqrt{1-\bar\alpha_{t-1}}\epsilon\sim\mathcal{N}(\sqrt{\bar{\alpha}_{t-1}}x_0,1-\bar\alpha_{t-1})
p ( x t − 1 ∣ x 0 ) = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ ∼ N ( α ˉ t − 1 x 0 , 1 − α ˉ t − 1 )
p ( x t ∣ x 0 ) = α ˉ t x 0 + 1 − α ˉ t ϵ N ( α ˉ t x 0 , 1 − α ˉ t ) p(x_t|x_0) = \sqrt{\bar\alpha_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon~\mathcal{N}(\sqrt{\bar\alpha_t}x_0,1-\bar\alpha_t)
p ( x t ∣ x 0 ) = α ˉ t x 0 + 1 − α ˉ t ϵ N ( α ˉ t x 0 , 1 − α ˉ t )
然后是p ( x t ∣ x t − 1 ) p(x_t|x_{t-1}) p ( x t ∣ x t − 1 )
p ( x t ∣ x t − 1 ) = α t x t − 1 + 1 − α t ϵ ∼ N ( α t x t − 1 , 1 − α t ) p(x_t|x_{t-1}) = \sqrt{\alpha_t}x_{t-1} + \sqrt{1-\alpha_t}\epsilon\sim\mathcal{N}(\sqrt\alpha_tx_{t-1},1-\alpha_t)
p ( x t ∣ x t − 1 ) = α t x t − 1 + 1 − α t ϵ ∼ N ( α t x t − 1 , 1 − α t )
这样我们不难推出:
p ( x t − 1 ∣ x t , x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t ) + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) p(x_{t-1}|x_t, x_0) \propto \exp\left(-\frac{1}{2}(\frac{\left(x_t - \sqrt{\alpha_{t}}x_{t-1}\right)^2}{\beta_t}) + \frac{(x_{t-1}-\sqrt{\bar\alpha_{t-1}}x_0)^2}{1-\bar\alpha_{t-1}} - \frac{(x_t - \sqrt{\bar\alpha_t }x_0)^2}{1-\bar\alpha_t}\right)
p ( x t − 1 ∣ x t , x 0 ) ∝ exp ( − 2 1 ( β t ( x t − α t x t − 1 ) 2 ) + 1 − α ˉ t − 1 ( x t − 1 − α ˉ t − 1 x 0 ) 2 − 1 − α ˉ t ( x t − α ˉ t x 0 ) 2 )
可以发现上式p ( x t − 1 ∣ x t , x 0 ) p(x_{t-1}|x_t, x_0) p ( x t − 1 ∣ x t , x 0 )
p ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 ( 1 − α t ) 1 − α ˉ t x 0 , ( 1 − α ˉ t − 1 1 − α ˉ t ( 1 − α t ) ) I ) p(x_{t-1}|x_t, x_0) = \mathcal{N}\left(x_{t-1}; \frac{\sqrt{\alpha_t}(1 - \bar\alpha_{t-1})}{1 - \bar\alpha_t}x_t + \frac{\sqrt{\bar\alpha_{t-1}}(1 - \alpha_t)}{1 - \bar\alpha_t}x_0,
\left(\frac{ 1 - \bar\alpha_{t-1}}{ 1 - \bar\alpha_t} ( 1-\alpha_t )\right)I\right)
p ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t α ˉ t − 1 ( 1 − α t ) x 0 , ( 1 − α ˉ t 1 − α ˉ t − 1 ( 1 − α t ) ) I )
上式看着较为复杂,稍微调整一下:
p ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ , σ 2 ) p(x_{t-1}|x_t, x_0) = \mathcal{N}\left(x_{t-1};\mu,\sigma^2\right)
p ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ , σ 2 )
μ = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 ( 1 − α t ) 1 − α ˉ t x 0 \mu = \frac{\sqrt{\alpha_t}(1 - \bar\alpha_{t-1})}{1 - \bar\alpha_t}x_t + \frac{\sqrt{\bar\alpha_{t-1}}(1 - \alpha_t)}{1 - \bar\alpha_t}x_0
μ = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t α ˉ t − 1 ( 1 − α t ) x 0
σ 2 = 1 − α ˉ t − 1 1 − α ˉ t ( 1 − α t ) \sigma^2 = \frac{ 1 - \bar\alpha_{t-1}}{ 1 - \bar\alpha_t} ( 1-\alpha_t )
σ 2 = 1 − α ˉ t 1 − α ˉ t − 1 ( 1 − α t )
我们先整理一下思路,现在我们推出的p ( x t − 1 ∣ x t , x 0 ) p(x_{t-1}|x_t,x_0) p ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) p θ ( x t − 1 ∣ x t ) p ( x t − 1 ∣ x t , x 0 ) p(x_{t-1}|x_t,x_0) p ( x t − 1 ∣ x t , x 0 ) p ( x t − 1 ∣ x t , x 0 ) p(x_{t-1}|x_t,x_0) p ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) p θ ( x t − 1 ∣ x t ) 均值 尽可能的对齐。
但观察均值公式,不难发现其中的x 0 x_0 x 0
x t = α ‾ t x 0 + 1 − α ‾ t ϵ ϵ ∼ N ( 0 , I ) x_t= \sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}\epsilon\quad\epsilon\sim\mathcal{N}(0,I)
x t = α t x 0 + 1 − α t ϵ ϵ ∼ N ( 0 , I )
将x 0 x_0 x 0 x 0 x_0 x 0
x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ ) x_0 = \frac{1}{\sqrt{\bar\alpha_t}}(x_t-\sqrt{1-\bar\alpha_t}\epsilon)
x 0 = α ˉ t 1 ( x t − 1 − α ˉ t ϵ )
代入μ \mu μ
μ = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 ( 1 − α t ) 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t ϵ ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + ( 1 − α t ) 1 − α ˉ t 1 α t ( x t − 1 − α ˉ t ϵ ) = α t ( 1 − α ˉ t − 1 ) + ( 1 − α t ) α t ( 1 − α ˉ t ) x t − ( 1 − α t ) 1 − α ˉ t α t ( 1 − α ˉ t ) ϵ = 1 − α ˉ t α t ( 1 − α ˉ t ) x t − 1 − α t α t 1 − α ˉ t ϵ = 1 α t x t − 1 − α t α t 1 − α ˉ t ϵ \begin{align*} \mu &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar\alpha_{t-1}}(1 - \alpha_t)}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar\alpha_t}} \left(x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon \right) \\ &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{(1 - \alpha_t)}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\alpha_t}} \left(x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon \right) \\ &= \frac{\alpha_t(1 - \bar{\alpha}_{t-1}) + (1 - \alpha_t)}{\sqrt{\alpha_t}(1 - \bar{\alpha}_t)} x_t - \frac{(1 - \alpha_t) \sqrt{1 - \bar{\alpha}_t}}{\sqrt{\alpha_t}(1 - \bar{\alpha}_t)} \epsilon \\ &= \frac{1 - \bar{\alpha}_t}{\sqrt{\alpha_t}(1 - \bar{\alpha}_t)} x_t - \frac{1 - \alpha_t }{\sqrt{\alpha_t}\sqrt{1 - \bar{\alpha}_t}} \epsilon \\ &= \frac{1}{\sqrt{\alpha_t}} x_t - \frac{1 - \alpha_t}{\sqrt{\alpha_t} \sqrt{1 - \bar{\alpha}_t}} \epsilon \end{align*}
μ = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t α ˉ t − 1 ( 1 − α t ) α ˉ t 1 ( x t − 1 − α ˉ t ϵ ) = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t ( 1 − α t ) α t 1 ( x t − 1 − α ˉ t ϵ ) = α t ( 1 − α ˉ t ) α t ( 1 − α ˉ t − 1 ) + ( 1 − α t ) x t − α t ( 1 − α ˉ t ) ( 1 − α t ) 1 − α ˉ t ϵ = α t ( 1 − α ˉ t ) 1 − α ˉ t x t − α t 1 − α ˉ t 1 − α t ϵ = α t 1 x t − α t 1 − α ˉ t 1 − α t ϵ
经过上述化简,我们成功将μ ( x 0 , x t ) ⇒ μ ( x t , ϵ ) \mu(x_0,x_t)\Rightarrow \mu(x_t,\epsilon) μ ( x 0 , x t ) ⇒ μ ( x t , ϵ )
此时,式子中未知的部分只剩下ϵ \epsilon ϵ x t , t x_t,t x t , t 神经网络 ( ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵ θ ( x t , t ) ϵ \epsilon ϵ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 ||\epsilon-\epsilon_\theta(x_t,t)||^2 ∣∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2
μ ≃ μ θ ( x t , t ) = 1 α t x t − 1 − α t α t 1 − α ˉ t ϵ θ ( x t , t ) \mu \simeq \mu_\theta(\mathbf{x}_t, t) = \frac{1}{\sqrt{\alpha_t}} \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{\alpha_t} \sqrt{1 - \bar{\alpha}_t}}
\epsilon_\theta(\mathbf{x}_t, t)
μ ≃ μ θ ( x t , t ) = α t 1 x t − α t 1 − α ˉ t 1 − α t ϵ θ ( x t , t )
以上便是DDPM整个流程的公式推导。
代码部分
详细代码可以看我fork的仓库Mudrobot/Diffusion_models_tutorial (github.com) 中的Diffusers_library.ipynb 文件进行理解,这里主要展示和讲解一下两个重要的过程以及训练和推理部分。
正向过程
1 2 3 4 5 6 7 8 def q_sample (self, x_start, t, noise=None ): if noise is None : noise = torch.randn_like(x_start) sqrt_alphas_cumprod_t = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape) sqrt_one_minus_alphas_cumprod_t = self._extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
最后一个return就是x t = α t x t − 1 + β t ϵ t ϵ t ∼ N ( 0 , I ) x_t = \sqrt{\alpha_t} x_{t-1} + \sqrt{\beta_t}\epsilon_t \quad \epsilon_t \sim \mathcal{N}(0, I) x t = α t x t − 1 + β t ϵ t ϵ t ∼ N ( 0 , I )
可以使用下面代码可视化一下输出结果:
1 2 3 4 5 6 7 8 for idx, t in enumerate ([0 , 50 , 100 , 200 , 499 ]): x_noisy = gaussian_diffusion.q_sample(x_start, t=torch.tensor([t])) noisy_image = (x_noisy.squeeze().permute(1 , 2 , 0 ) + 1 ) * 127.5 noisy_image = noisy_image.numpy().astype(np.uint8) plt.subplot(1 , 5 , 1 + idx) plt.imshow(noisy_image) plt.axis("off" ) plt.title(f"t={t} " )
训练目标
训练目标如之前最后所说,就是使用神经网络(第7行的model)去预测之前公式中对图像添加的噪声ϵ \epsilon ϵ ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵ θ ( x t , t ) ϵ \epsilon ϵ
代码如下:
1 2 3 4 5 6 7 8 9 def train_losses (self, model, x_start, t ): noise = torch.randn_like(x_start) x_noisy = self.q_sample(x_start, t, noise=noise) predicted_noise = model(x_noisy, t) loss = F.mse_loss(noise, predicted_noise) return loss
训练部分
理解到逆向过程后,接着我们来看一下训练过程,其实就是对于每个batch中的所有图像都需要随机采样一个时间点,用于计算要加的噪声量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 epochs = 10 for epoch in range (epochs): for step, (images, labels) in enumerate (train_loader): optimizer.zero_grad() batch_size = images.shape[0 ] images = images.to(device) t = torch.randint(0 , timesteps, (batch_size,), device=device).long() loss = gaussian_diffusion.train_losses(model, images, t) if step % 200 == 0 : print ("Loss:" , loss.item()) loss.backward() optimizer.step()
逆向过程
训练的时候模型学习的是ϵ \epsilon ϵ ϵ \epsilon ϵ ϵ t \epsilon_t ϵ t μ \mu μ 采样 当前步的降噪噪声ϵ t ∈ N ( μ , σ ) \epsilon_t\in\mathcal{N}(\mu,\sigma) ϵ t ∈ N ( μ , σ ) σ \sigma σ
预测当前时间步噪声均值和方差的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def q_posterior_mean_variance (self, x_start, x_t, t ): posterior_mean = ( self._extract(self.posterior_mean_coef1, t, x_t.shape) * x_start + self._extract(self.posterior_mean_coef2, t, x_t.shape) * x_t ) posterior_variance = self._extract(self.posterior_variance, t, x_t.shape) posterior_log_variance_clipped = self._extract(self.posterior_log_variance_clipped, t, x_t.shape) return posterior_mean, posterior_variance, posterior_log_variance_clipped def p_mean_variance (self, model, x_t, t, clip_denoised=True ): pred_noise = model(x_t, t) x_recon = self.predict_start_from_noise(x_t, t, pred_noise) if clip_denoised: x_recon = torch.clamp(x_recon, min =-1. , max =1. ) model_mean, posterior_variance, posterior_log_variance = \ self.q_posterior_mean_variance(x_recon, x_t, t) return model_mean, posterior_variance, posterior_log_variance
采样并消除噪声代码如下所示:
第10行中,对数方差乘0.5取指数的含义是,将对数方差转化为方差后开根号得标准差。σ = σ 2 = e log ( σ 2 ) = e 0.5 ⋅ log ( σ 2 ) \sigma = \sqrt{\sigma^2} = \sqrt{e^{\log(\sigma^2)}} = e^{0.5 \cdot \log(\sigma^2)} σ = σ 2 = e l o g ( σ 2 ) = e 0.5 ⋅ l o g ( σ 2 )
1 2 3 4 5 6 7 8 9 10 11 @torch.no_grad() def p_sample (self, model, x_t, t, clip_denoised=True ): model_mean, _, model_log_variance = self.p_mean_variance(model, x_t, t, clip_denoised=clip_denoised) noise = torch.randn_like(x_t) nonzero_mask = ((t != 0 ).float ().view(-1 , *([1 ] * (len (x_t.shape) - 1 )))) pred_img = model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise return pred_img
推理部分
理解了上面的逆向过程后,推理部分的生成就非常好理解了。就是不断的调用p_sample函数逐渐从一个全噪声生成图像的过程(主函数先调用sample)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @torch.no_grad() def p_sample_loop (self, model, shape ): batch_size = shape[0 ] device = next (model.parameters()).device img = torch.randn(shape, device=device) imgs = [] for i in tqdm(reversed (range (0 , timesteps)), desc='sampling loop time step' , total=timesteps): img = self.p_sample(model, img, torch.full((batch_size,), i, device=device, dtype=torch.long)) imgs.append(img.cpu().numpy()) return imgs @torch.no_grad() def sample (self, model, image_size, batch_size=8 , channels=3 ): return self.p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
如果要控制diffusion生成特定类别的图像,会使用classifier free guidance方法,后续会讲解。
该ipynb文件最后对于MNIST手写数据集的生成效果如下: