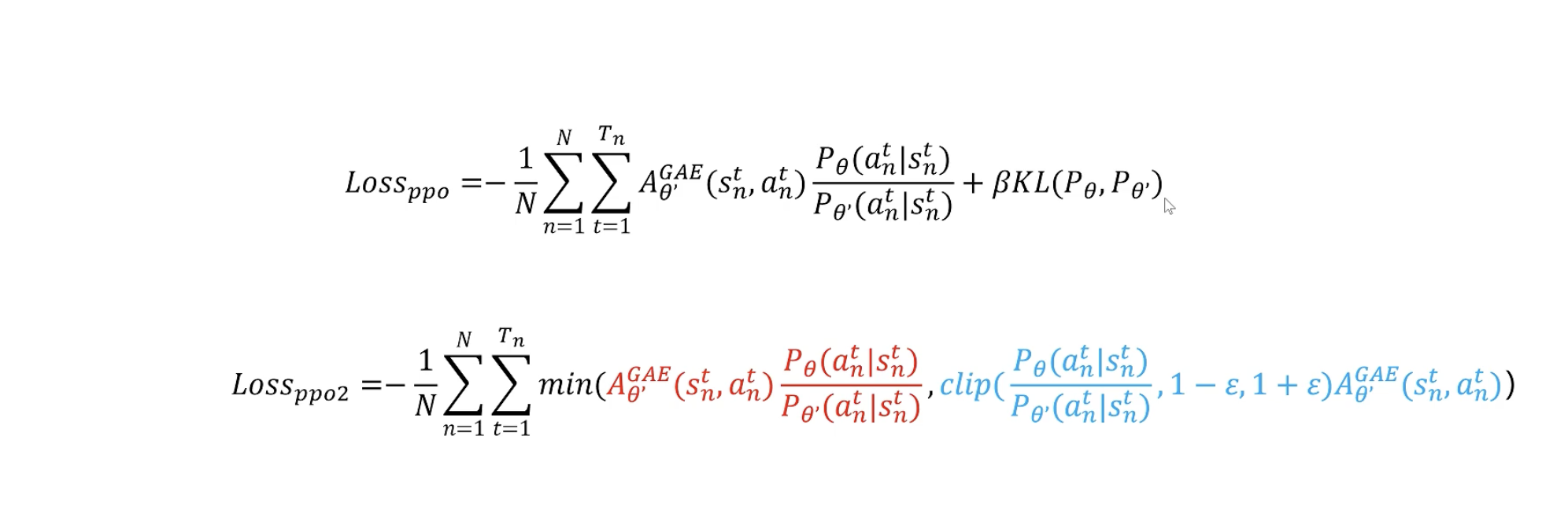强化学习基础
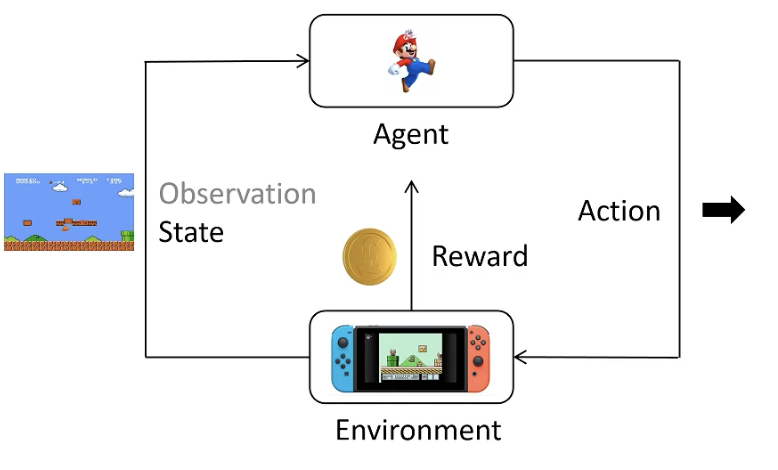
- Action Space
- Reward
- Trajectory
- Return(回报)
目的:训练一个Policy网络,在所有状态S下,给出相应的Action,得到Return的期望最大
目的:训练一个Policy网络,在所有的Trajectory中,给出相应的Action,得到Return的期望最大。
也就是最大化:, 可以使用梯度上升法。
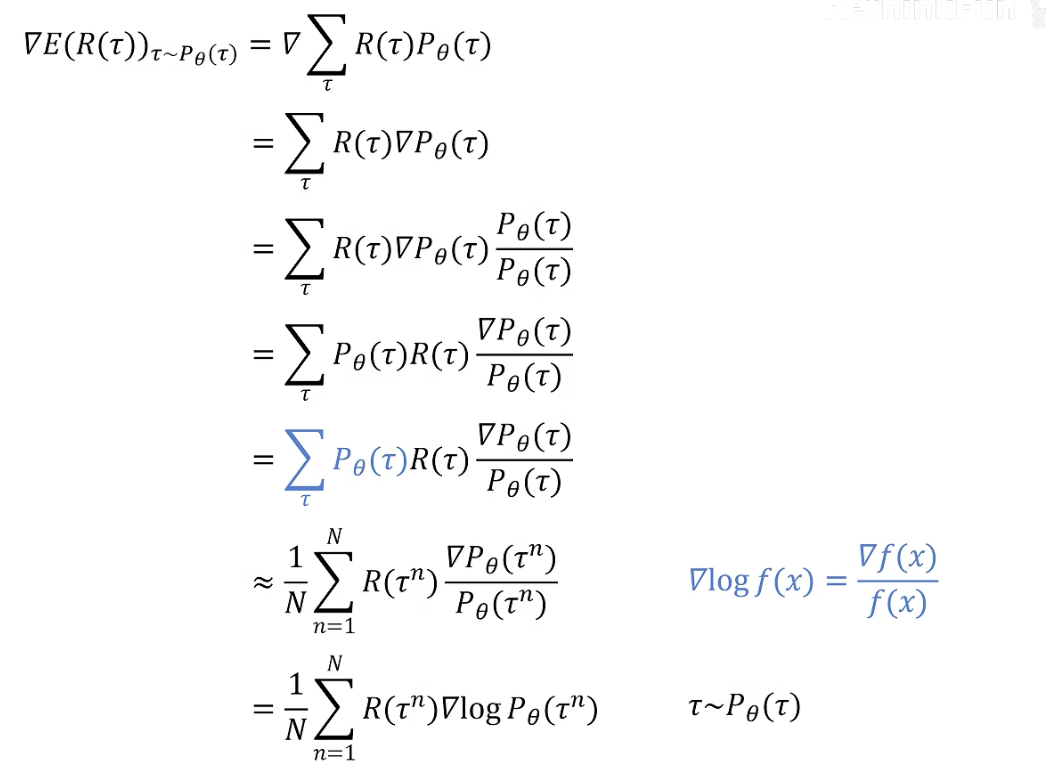
在强化学习中,我们认为下一个状态的概率仅由当前状态和要做的动作决定,所以可以被表示为:
由于一般为常数,可以被忽略,继续化简上式可得
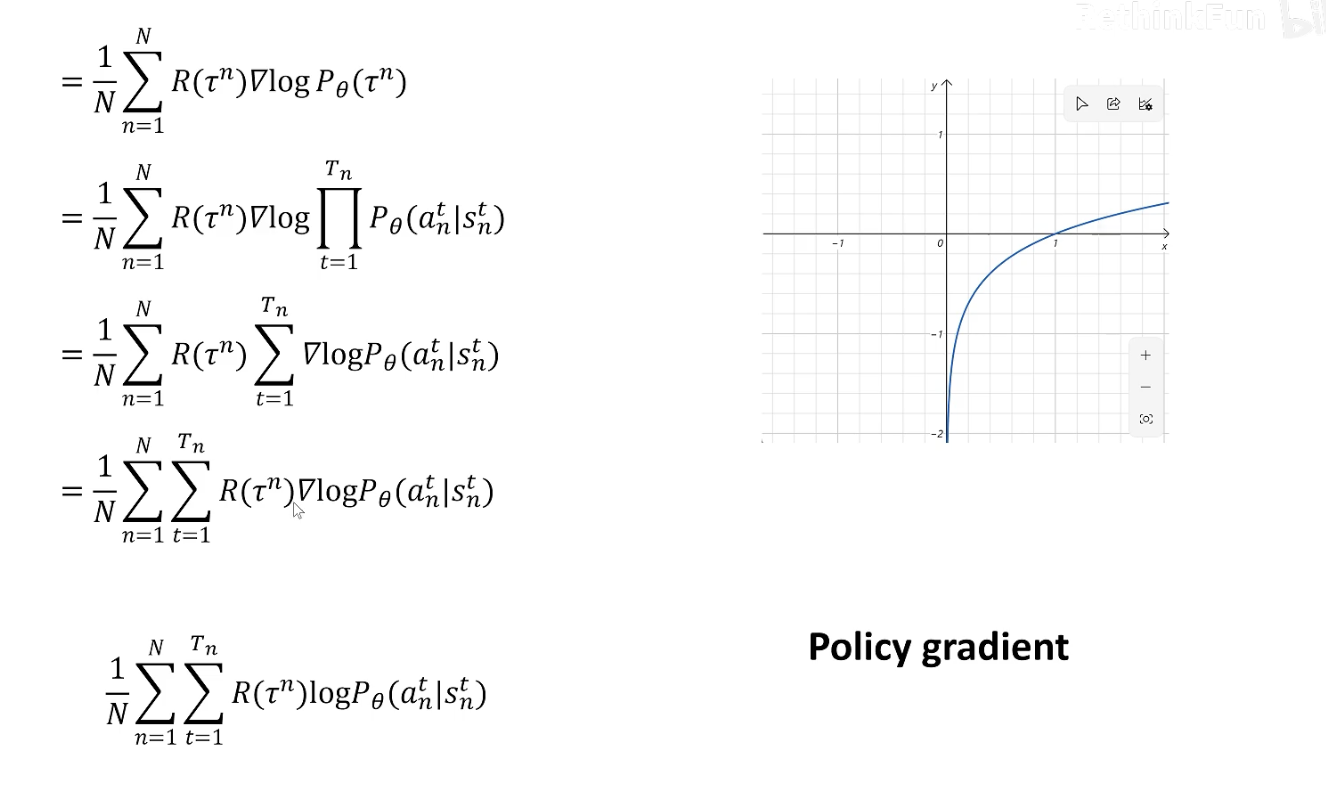
该导数的直观意义是,如果 是大于0的,则增大所有执行当前trajectory动作的概率(),反之减少。该算法被称为 Policy gradient 算法。
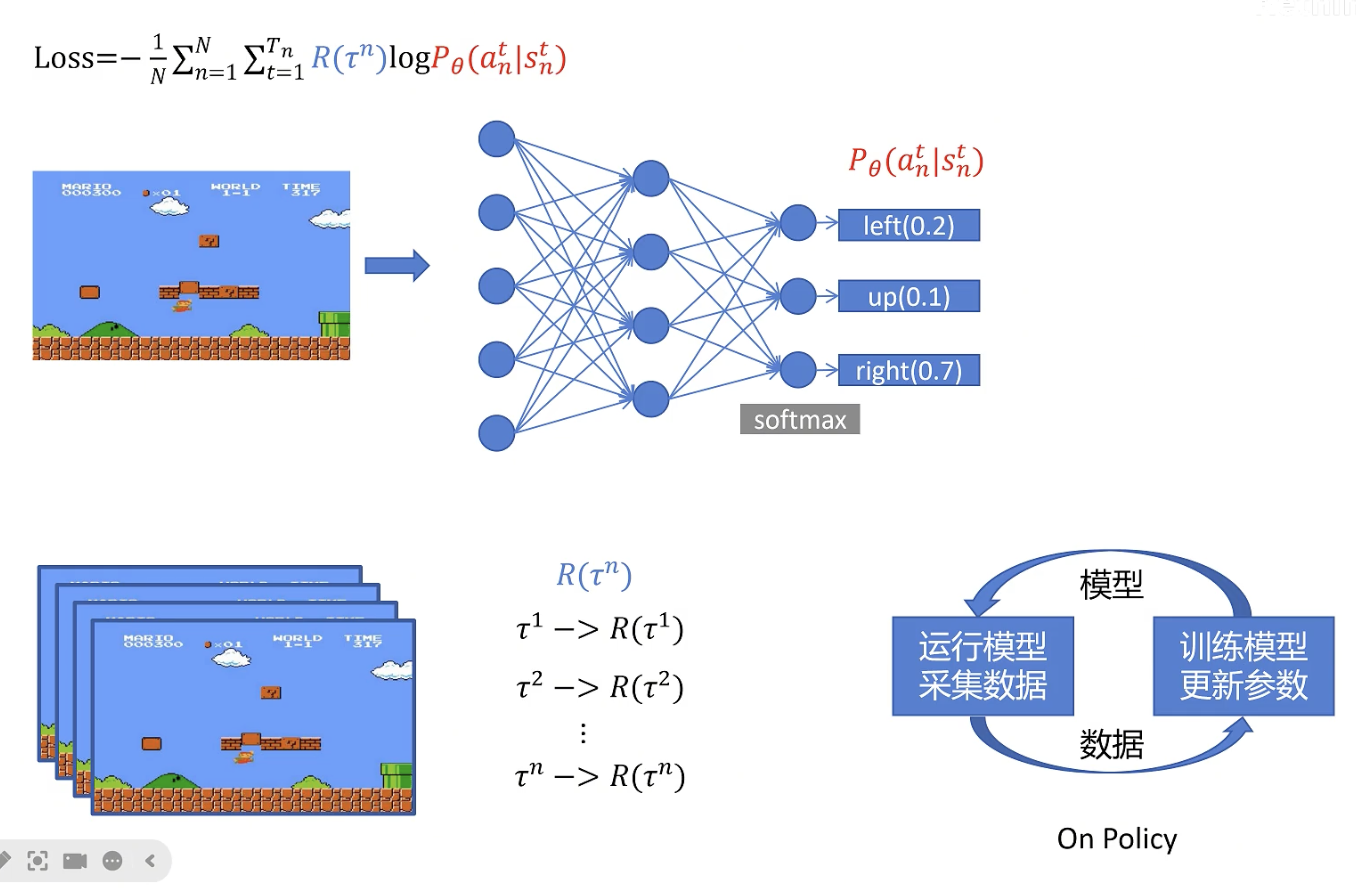
Policy Gradient是一个on policy的算法,每次让agent完n轮游戏,然后用n轮的trajectory更新策略。
缺点:收集的数据只被用于更新一回,大量数据收集,导致时间效率低。
可以优化的地方
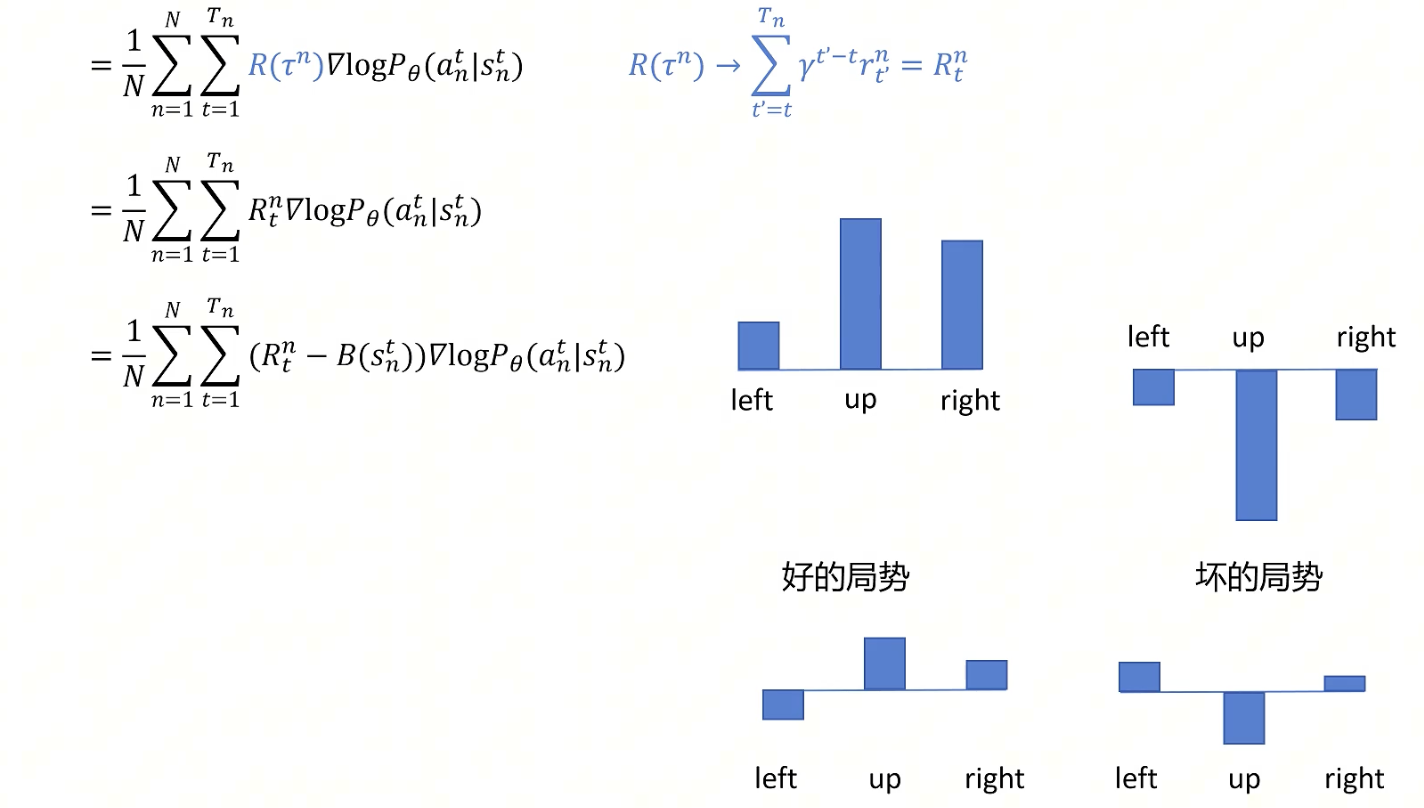
- 给添加一个折扣因子。(一个动作只能影响后面的reward,且后面的reward我们应该尽快拿到更好,所以添加了一个折扣因子)
- 在好的局势下,所有动作的概率都会被提升,坏的局势下所有动作的概率都会被减少。添加一个baseline(相减)可以让部分动作概率提升,部分动作概率减少,使学习收敛更迅速。
具体优化见下图:
接下来回顾三个常见的强化学习新概念:

然后如上图所示,可以使用Advantage Function替换掉原式子中的 ,但是我们此时在实现的过程中还是需要训练两个神经网络分别拟合Action-Value Function以及State-Value Function。有没有办法只训练一个网络呢?

观察红框不难发现,此时Advantage Function中只含有State-Value Function我们只需要训练一个网络即可。
为了使右侧式子表示的更为简洁,定义 如下图所示:
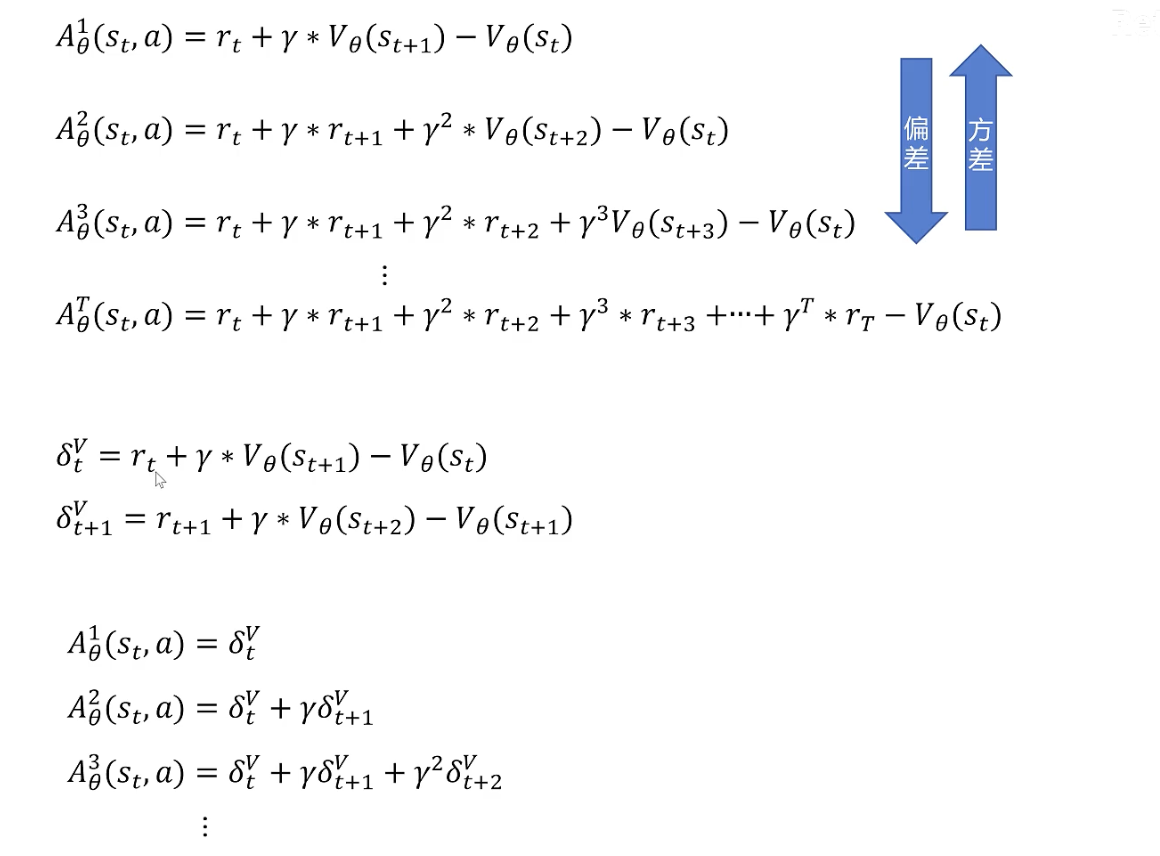
从上图不难理解,随着优势函数阶数的增加,估计的偏差越小,方差越大。为了更好的估计真实的优势函数(平衡方差和偏差),我们下面引入GAE算法(如下图所示)。
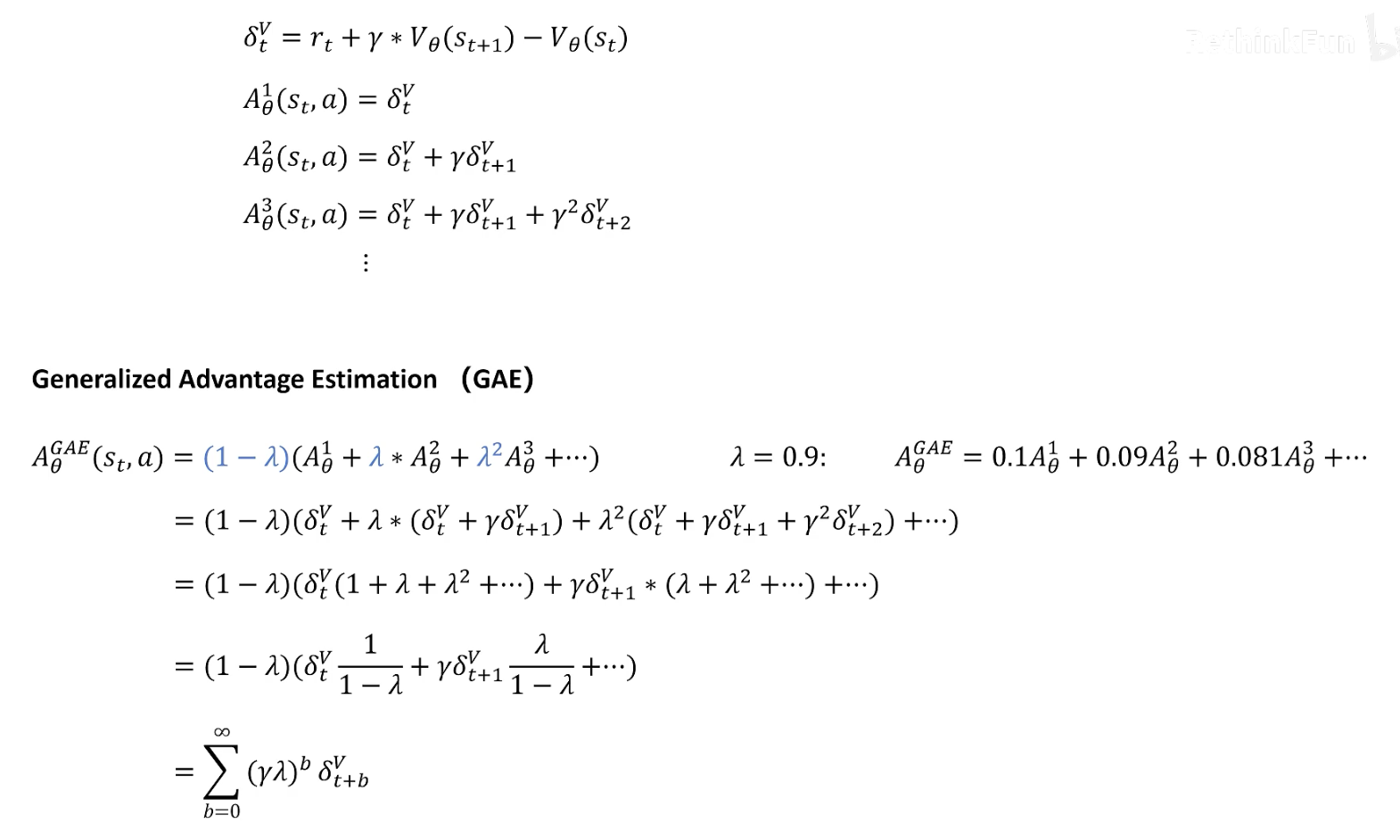
最后总结下上面推到出来最为重要的几个公式(见下图):
- GAE估计的优势函数
- 优化后的策略目标
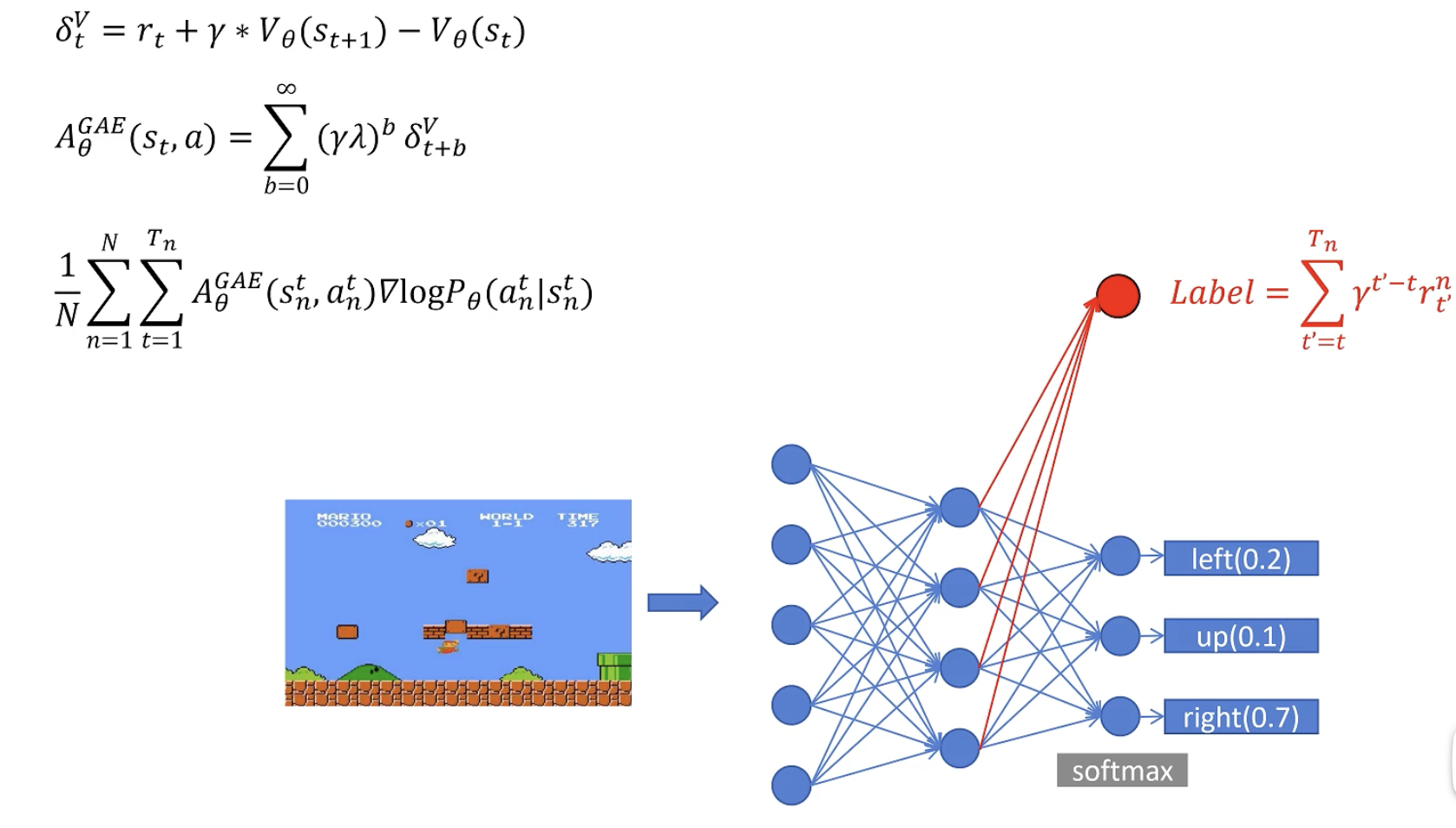
其中,状态价值函数使用神经网络进行拟合,和策略函数共用参数。(红色label代表的是拟合估计的V和真实的折扣回报值)
PPO
之前On Policy所存在的问题已经简单介绍过了,主要是采集的数据只能够用于训练一次神经网络,有点浪费,时间效率低。
PPO对这个On Policy进行了优化,让每次采样的数据可以被用于训练多次来优化网络参数。
重要性采样:如何让AI「吃老本」还不翻车?
重要性采样在PPO中的作用,可以理解为“用旧经验学新招,但避免翻车”。比如你学骑自行车时,用之前摔跤的经验调整动作,但又不让新动作和旧动作差别太大。PPO通过给旧策略的数据加上“调整系数”(重要性权重),让新策略能复用这些数据更新自己,同时限制调整幅度(比如用clip函数“剪掉”过大的改动),防止步子迈太大导致策略崩坏。这样既能高效利用数据,又能稳定训练。
1. 从On-Policy的痛点说起
想象你正在学骑自行车(训练策略θ),传统On-Policy算法就像一位严格的教练:
- 规则:每次调整动作(更新θ)后,必须重新上路骑行(采样新轨迹τ∼pθ),记录摔倒的姿势。
- 问题:哪怕只是微调了车把角度,之前所有摔倒的数据全部作废。效率极低,且95%的时间浪费在重复采样上!
此时,一个灵魂拷问诞生了:能否用历史摔倒数据(旧策略)指导新动作(新策略)?
答案就是重要性采样(Importance Sampling)。
2. 重要性采样的直观意义
2.1 二手书定价的统计哲学
假设你想计算某绝版书在书店的均价(分布p(x)),但只能从二手市场(分布q(x))收集数据。直接计算二手市场的均价会偏高,因为绝版书被炒高价。
解决方法:为每本书的价格乘上一个修正系数(= 书店定价/二手市场定价)。例如:
- 某书在书店原价50元,二手市场卖100元,则修正系数=0.5
- 最终统计时,这本书的贡献是:100元 × 0.5 = 50元(还原真实价值)
这里的修正系数就是重要性权重 ,它抵消了分布差异带来的偏差。
2.2 回到自行车:如何用旧动作学新招?
假设旧策略θ_old的摔倒数据中有一个动作:“腿抬高10cm时摔倒”。现在新策略θ想尝试“腿抬8cm”。直接复用旧数据会有两个问题:
- 偏差:旧数据中“抬10cm”的频率可能和新策略“抬8cm”的实际概率不同。
- 风险:如果盲目参考旧动作,可能学得比原来更差(梯度爆炸)。
重要性采样的作用:
- 给每个旧动作加上一个可信度标签(重要性权重=新策略产生该动作的概率 / 旧策略的概率)。
- 如果新策略θ认为“抬10cm”的概率是旧策略的80%,则这个动作的梯度更新权重就是0.8。
效果:相当于教练说:“你过去抬10cm摔了,但现在你只打算抬8cm,所以这个旧动作的参考价值打8折。”
3. 数学视角:期望修正与概率比
3.1 原始On-Policy梯度
- 痛点:每次更新θ后,必须重新采样τ∼pθ(τ),成本高昂。
3.2 重要性采样改造后的梯度
- 魔法:采样分布从新策略pθ切换到旧策略q,但通过乘上概率比 修正偏差。
- 物理意义:
- 若新策略pθ比旧策略q更倾向于某个τ(即),则放大该τ的梯度贡献。
- 反之则缩小,甚至忽略(如PPO的Clip操作)。
4. 重要性采样的隐患:方差爆炸
4.1 为什么不能无脑复用旧数据?
回到二手书例子:如果某书在书店原价50元,但二手市场标价10,000元(概率比=0.005),则修正后的价格为10,000×0.005=50元。看似合理,但问题在于:
- 若这本书在二手市场被频繁交易(采样多),则它会主导整体均价的计算,导致统计结果波动极大。
对应到RL中:若新旧策略在某个轨迹τ上的概率差异极大(例如),则少量τ的样本会主导梯度更新,使得训练不稳定。
4.2 PPO的智慧:给「吃老本」加上安全绳
PPO的解决方案简单粗暴——限制重要性权重的幅度:
- 计算原始权重:
- 用Clip函数裁剪:
直观解释:
- 教练说:“旧动作和新动作差异超过±10%的部分我不认,避免你乱改动作摔得更惨。”
- 数学上,这限制了梯度更新的最大步长,避免单一样本主导学习过程。
5. 总结:重要性采样的双重价值
- 高效性:打破On-Policy的采样枷锁,让AI能复用历史数据,大幅提升训练效率。
- 安全性:通过概率比和Clip机制,在「大胆创新」和「谨慎迭代」之间找到平衡,避免策略崩溃。
如同学骑自行车:
- 看自己过去的摔倒录像(重要性采样)比每次都真摔(On-Policy)更高效。
- 但模仿时需注意:“上次抬腿10cm摔了,这次试试8cm,但绝不突然抬腿20cm(Clip限制)”。
目标函数更新
理解了重要性采样,我们便可用其来更新我们的目标函数,将原来On-Policy的学习转为Off-Policy。
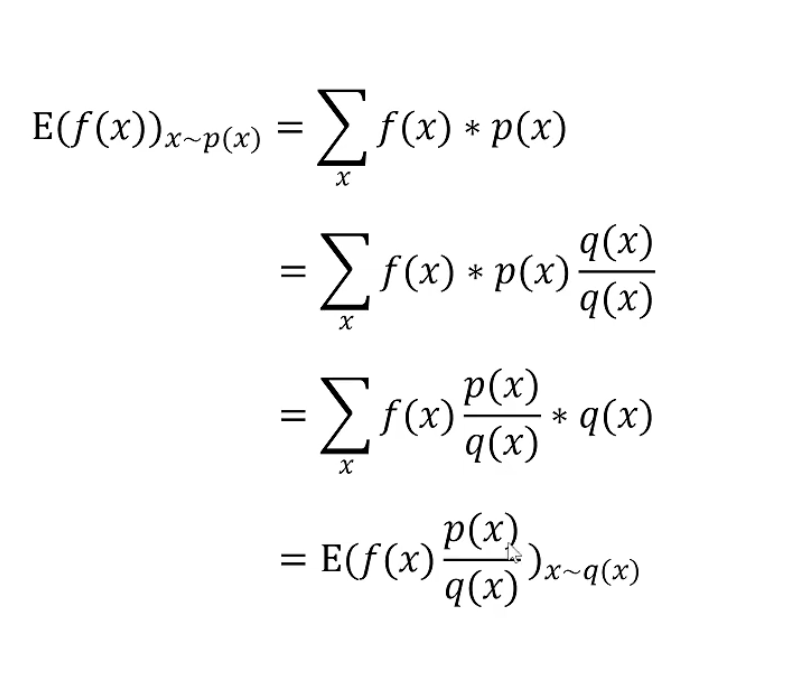

其中第一步是原始的On-Policy损失函数,第二步变为了Off-Policy损失函数(为参考策略,参考策略用于采样,并可以用于多次训练优化)。最后的Loss就是PPO算法的损失函数。
但是对于参考策略和现有的策略还是有一些限制,就是参考策略和现有的策略不能相差太大。不然训练效果会非常不好。
可以通过下面的方式进行约束:
- 增加KL散度正则化项进行约束
- 使用CLIP函数,防止训练的策略和参考的策略偏差过大