In [3]: from torch import nn In [4]: rnn=nn.RNN(100,20) In [5]: rnn._parameters.keys() Out[5]: odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0']) In [6]: rnn.weight_hh_l0.shape,rnn.weight_ih_l0.shape Out[6]: (torch.Size([20, 20]), torch.Size([20, 100])) In [7]: rnn.bias_hh_l0.shape,rnn.bias_ih_l0.shape Out[7]: (torch.Size([20]), torch.Size([20]))
In [3]: from torch import nn In [4]: rnn=nn.RNN(input_size=100, hidden_size=20,num_layers=1) In [5]: print(rnn) RNN(100, 20) In [6]: x=torch.randn(10,3,100) In [7]: out,ht=rnn(x,torch.zeros(1,3,20)) In [8]: print(out.shape) torch.Size([10, 3, 20])
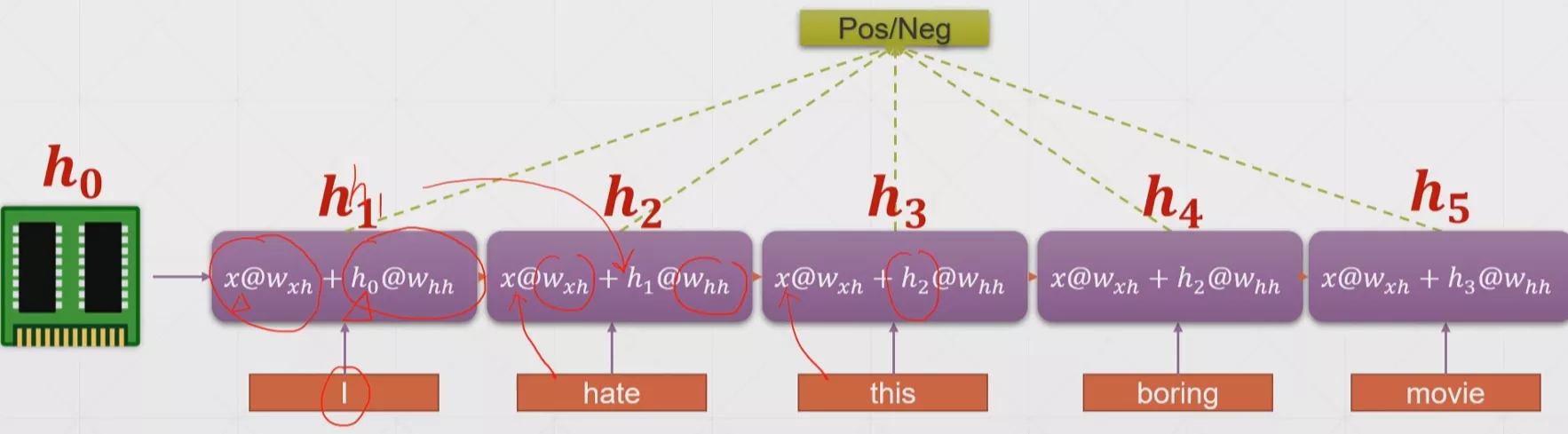
仔细阅读代码会发现和前面说的一样,很好的验证了前面我们说的正确性。
多层RNN
原理一样,这里放个代码来观察一下PyTorch中RNN模块的参数定义和多层RNN设计规则。
1 2 3 4 5 6 7 8 9
In [3]: from torch import nn In [4]: rnn=nn.RNN(100,10,num_layers=2) In [5]: rnn._parameters.keys() Out[5]: odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0', 'weight_ih_l1', 'weight_hh_l1', 'bias_ih_l1', 'bias_hh_l1']) In [6]: rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape Out[6]: (torch.Size([10, 10]), torch.Size([10, 100])) In [7]: rnn.weight_hh_l1.shape, rnn.weight_ih_l1.shape Out[7]: (torch.Size([10, 10]), torch.Size([10, 10]))
In [3]: from torch import nn In [4]: rnn=nn.RNN(input_size=100,hidden_size=20,num_layers=4) In [5]: print(rnn) RNN(100, 20, num_layers=4) In [6]: x=torch.randn(10,3,100) In [7]: out,h=rnn(x) In [8]: print(out.shape,h.shape) torch.Size([10, 3, 20]) torch.Size([4, 3, 20])
In [3]: from torch import nn In [4]: cell1=nn.RNNCell(100,20) In [5]: h1=torch.zeros(3,20) In [6]: for xt in x: ...: h1=cell1(xt,h1) In [7]: print(h1.shape) torch.Size([3,20])
双层RNN
1 2 3 4 5 6 7 8 9 10
In [3]: from torch import nn In [4]: cell1=nn.RNNCell(100,30) In [5]: h1=torch.zeros(3,30) In [6]: cell2=nn.RNNCell(30,20) In [7]: h2=torch.zeros(3,20) In [8]: for xt in x: ...: h1=cell1(xt,h1) ...: h2=cell2(h1,h2) In [9]: print(h2.shape) torch.Size([3,20])
loss = criterion(output, y) model.zero_grad() loss.backward() # for p in model.parameters(): # print(p.grad.norm()) # torch.nn.utils.clip_grad_norm_(p, 10) optimizer.step()
ifiter % 100 == 0: print("Iteration: {} loss {}".format(iter, loss.item()))
self.rnn = nn.RNN( input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True, ) for p in self.rnn.parameters(): nn.init.normal_(p, mean=0.0, std=0.001)
self.linear = nn.Linear(hidden_size, output_size)
defforward(self, x, hidden_prev):
out, hidden_prev = self.rnn(x, hidden_prev) # [b, seq, h] out = out.view(-1, hidden_size) out = self.linear(out) out = out.unsqueeze(dim=0) return out, hidden_prev
model = Net() criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr)
hidden_prev = torch.zeros(1, 1, hidden_size)
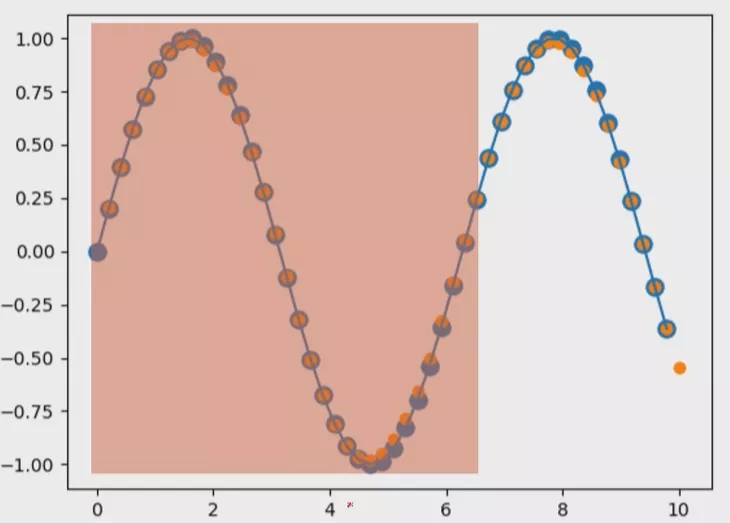
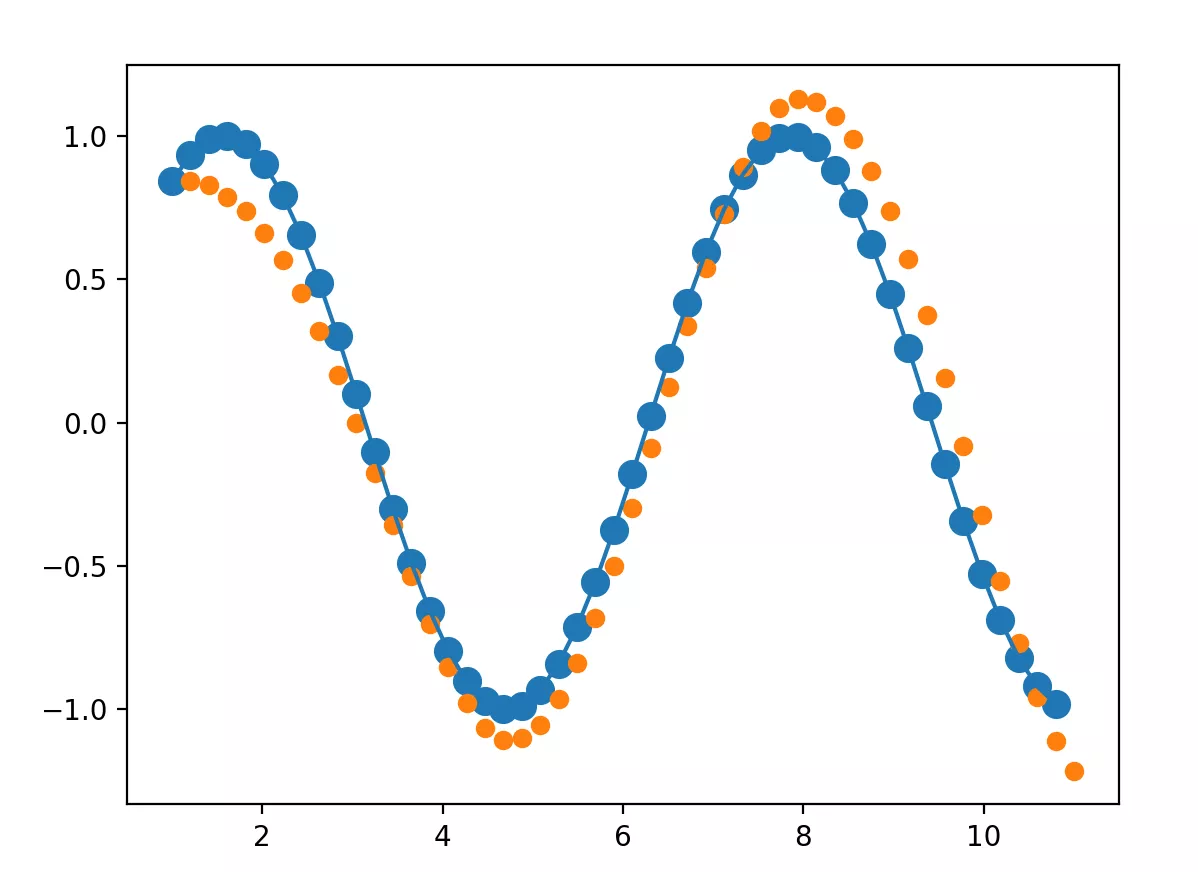
foriterinrange(6000): start = np.random.randint(3, size=1)[0] time_steps = np.linspace(start, start + 10, num_time_steps) data = np.sin(time_steps) data = data.reshape(num_time_steps, 1) x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
loss = criterion(output, y) model.zero_grad() loss.backward() # for p in model.parameters(): # print(p.grad.norm()) # torch.nn.utils.clip_grad_norm_(p, 10) optimizer.step()
ifiter % 100 == 0: print("Iteration: {} loss {}".format(iter, loss.item()))
start = np.random.randint(3, size=1)[0] time_steps = np.linspace(start, start + 10, num_time_steps) data = np.sin(time_steps) data = data.reshape(num_time_steps, 1) x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
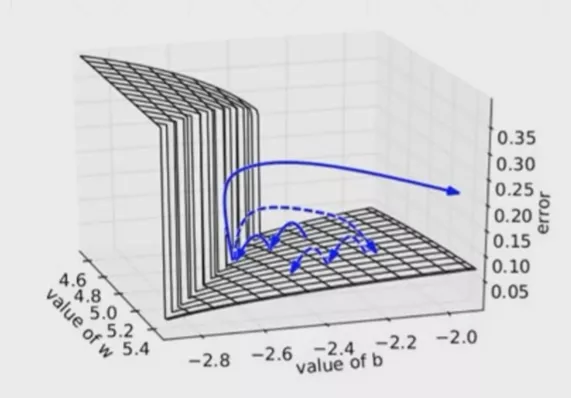
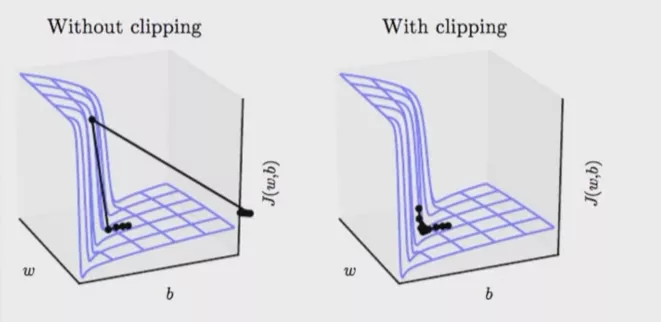
loss = criterion(output,y) model.zero_grad() loss.backward() for p in model.parameters(): print(p.grad.norm()) torch.nn.utils.clip_grad_norm_(p,10) # <10 optimizer.step()
In [3]: from torch import nn In [4]: lstm=nn.LSTM(input_size=100, hidden_size=20, num_layers=4) In [5]: lstm Out[5]: LSTM(100, 20, num_layers=4) In [6]: x=torch.randn(10,3,100) In [7]: out,(h,c)=lstm(x) In [8]: out.shape,h.shape,c.shape Out[8]: (torch.Size([10, 3, 20]), torch.Size([4, 3, 20]), torch.Size([4, 3, 20]))
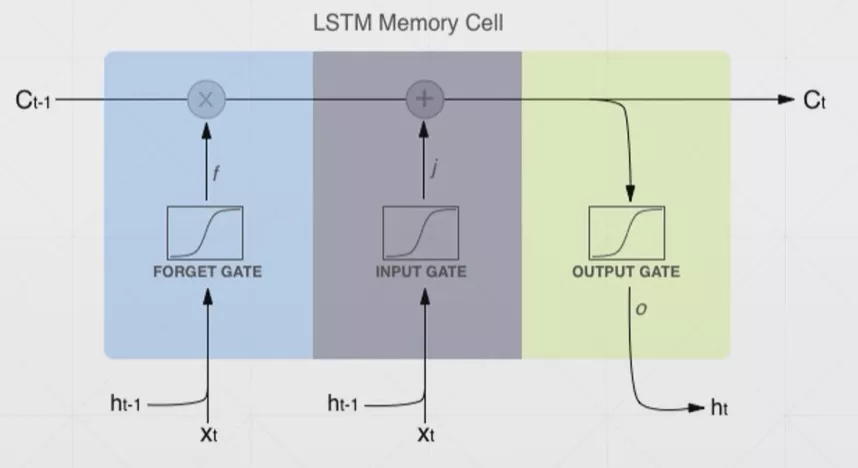
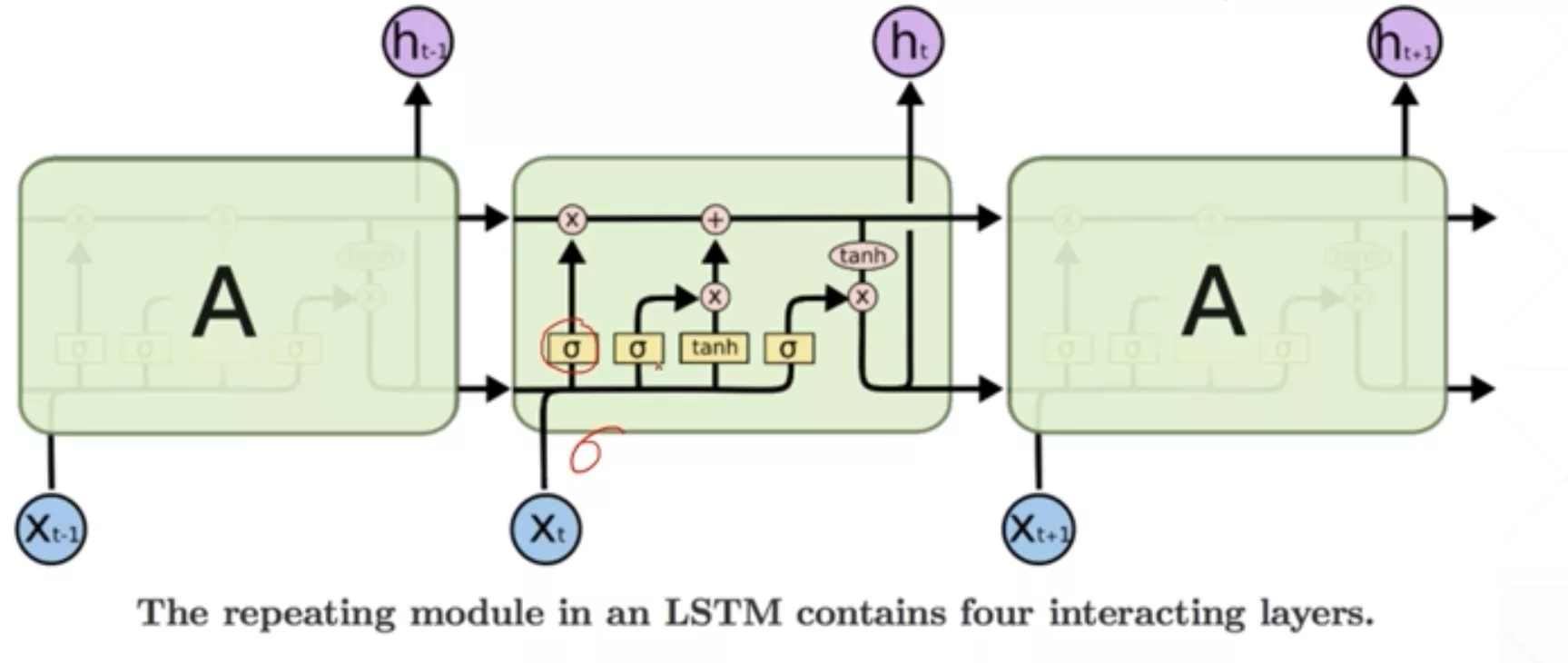
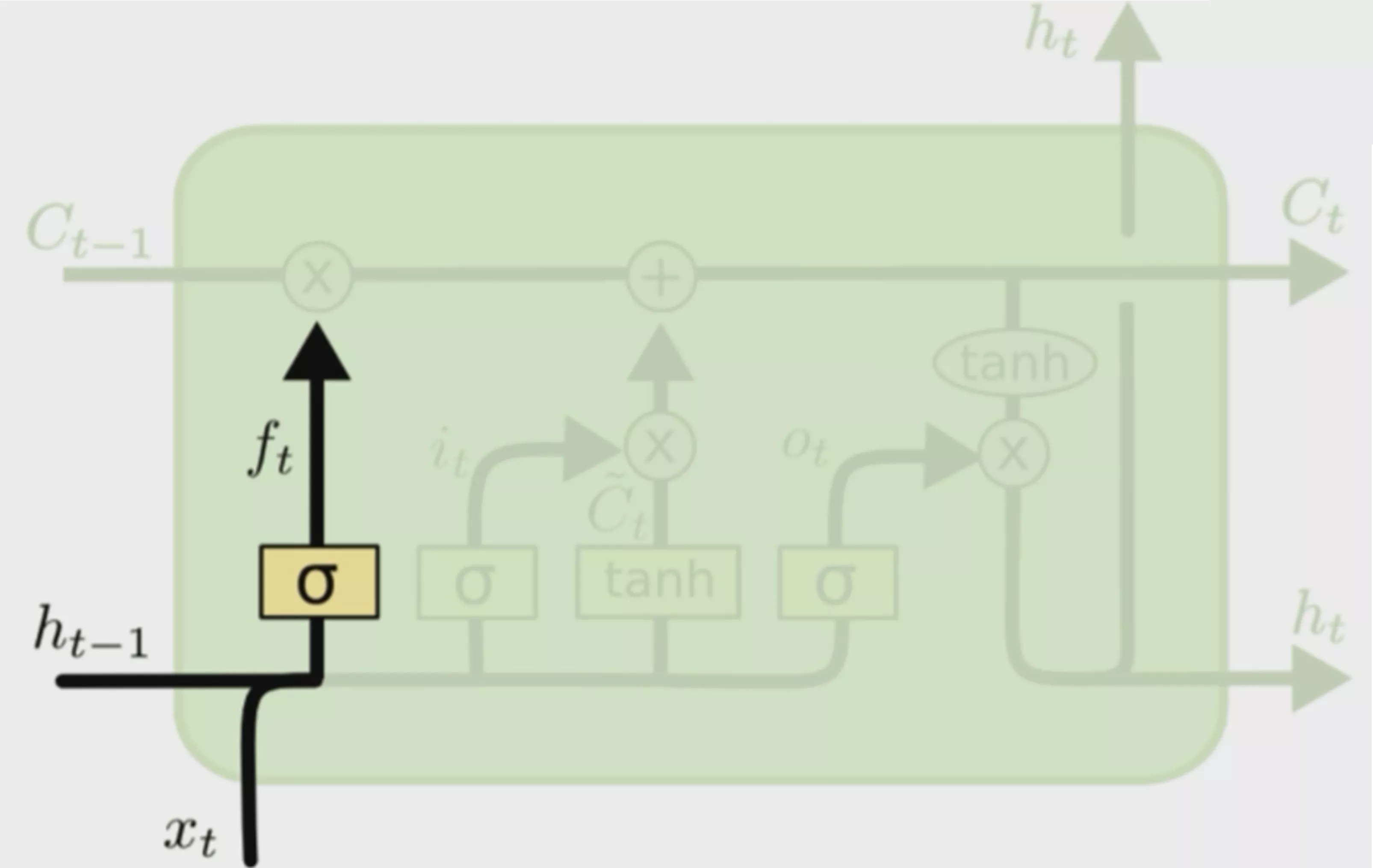
其实和原来的RNN使用差别不是非常大
nn.LSTMCell
__init()__
和nn.LSTM初始化操作一样:
nn.LSTM(input_size,hidden_size,num_layers)
LSTMCell.forward()
1
ht,ct=lstmcell(xt,[ht_1,ct_1])
对于一个输入是[10,3,100]的数据,使用上述方法需要送入10次,每次送入大小是[3,100]
同理,相比LSTM,LSTMCell更加的灵活,我们更推荐这样的方式
同上,下面还是简单给出一个例子,帮助理解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
In [3]: from torch import nn In [4]: xt=torch.randn(10,3,100) In [5]: cell1=nn.LSTMCell(input_size=100,hidden_size=30) In [6]: cell2=nn.LSTMCell(input_size=30,hidden_size=20) In [7]: h1=torch.zeros(3,30) In [8]: c1=torch.zeros(3,30) In [9]: h2=torch.zeros(3,20) In [10]: c2=torch.zeros(3,20) In [11]: for x in xt: ...: h1,c1=cell1(x,[h1,c1]) ...: h2,c2=cell2(h1,[h2,c2]) In [12]: h2.shape,c2.shape Out[12]: (torch.Size([3, 20]), torch.Size([3, 20]))
LSTM情感分类实战
安利:Google CoLab
免费12H训练
免费K80GPU
界面类似Jupyter,我们只需要把我们的代码扔上去就可以跑啦。
数据导入
1 2 3 4 5
TEXT = data.Field(tokenize='spacy') LABEL = data.LabelField(dtype=torch.float) train_data, test_data = datasets.IMDB.splits(TEXT, LABEL) print('len of train data:', len(train_data)) print('len of test data:', len(test_data))
# -*- coding: utf-8 -*- """lstm Automatically generated by Colaboratory. Original file is located at https://colab.research.google.com/drive/1GX0Rqur8T45MSYhLU9MYWAbycfLH4-Fu """