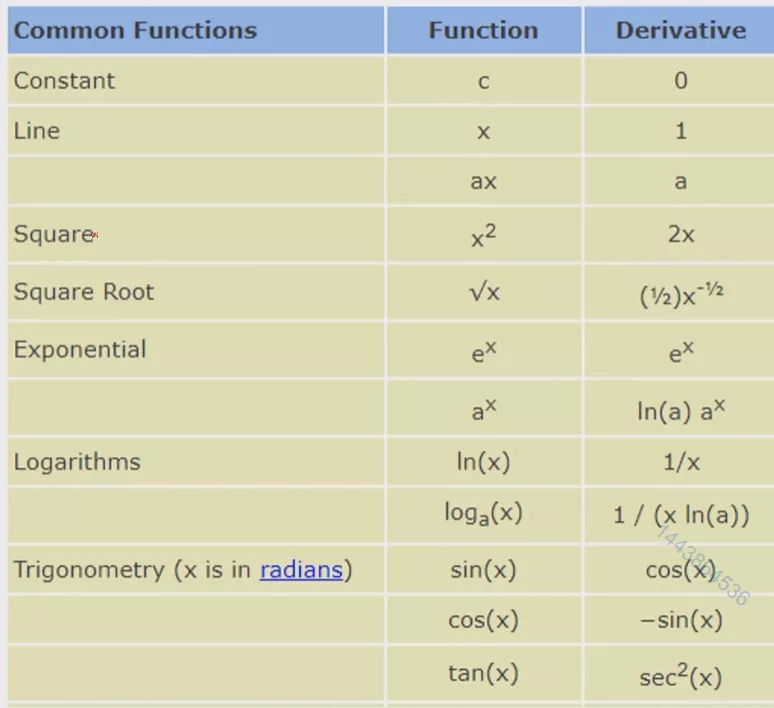
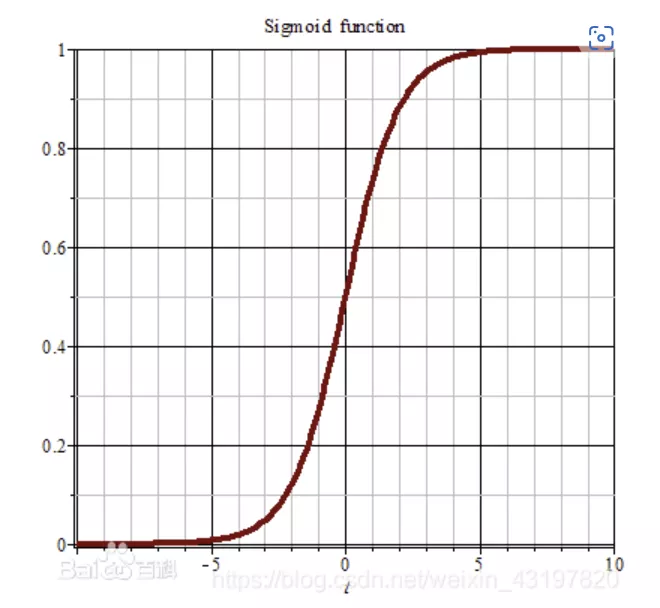
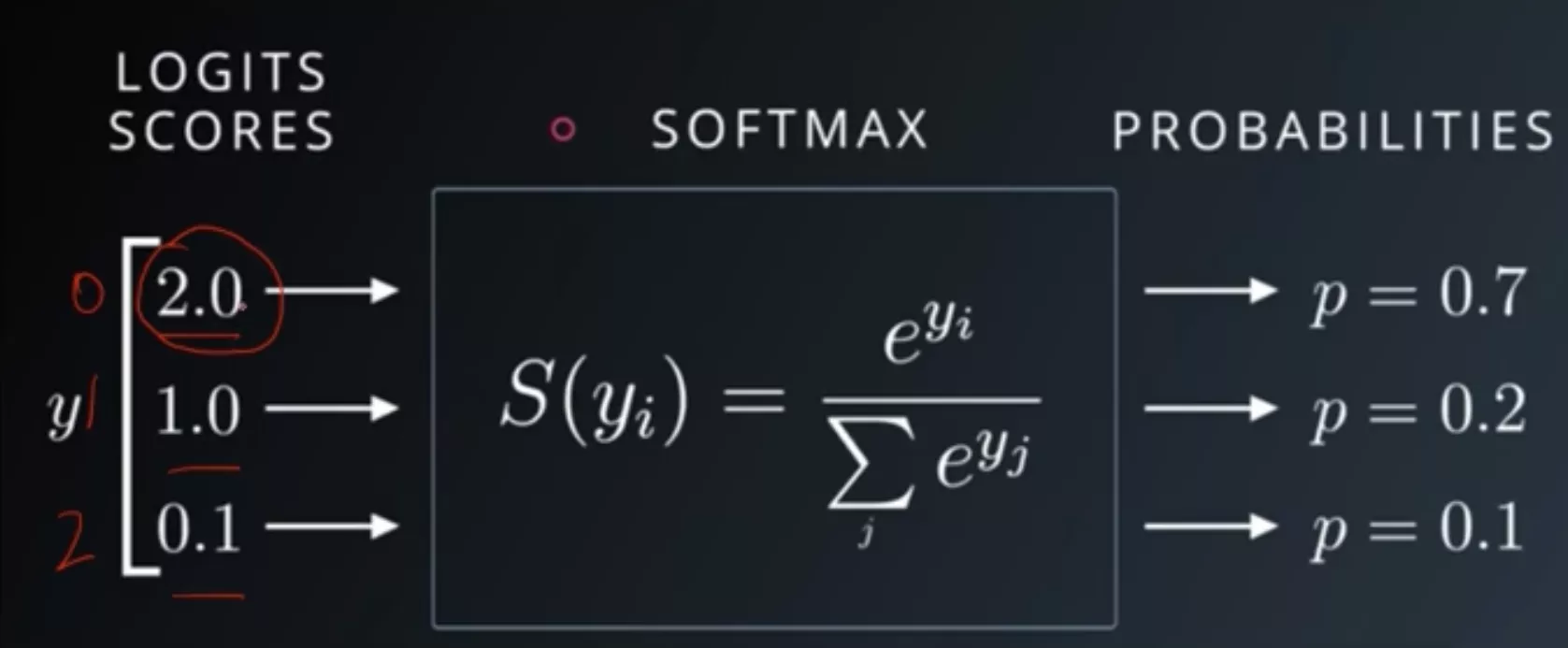In [3]: a=torch.linspace(-100,100,10) In [4]: a Out[4]: tensor([-100.0000, -77.7778, -55.5556, -33.3333, -11.1111, 11.1111, 33.3333, 55.5556, 77.7778, 100.0000]) In [5]: torch.sigmoid(a) Out[5]: tensor([0.0000e+00, 1.6655e-34, 7.4564e-25, 3.3382e-15, 1.4945e-05, 9.9999e-01, 1.0000e+00, 1.0000e+00, 1.0000e+00, 1.0000e+00]) In [6]: from torch.nn import functional as F In [7]: F.sigmoid(a) D:\App\Anaconda\envs\pytorch\lib\site-packages\torch\nn\functional.py:1806: UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead. warnings.warn("nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.") Out[7]: tensor([0.0000e+00, 1.6655e-34, 7.4564e-25, 3.3382e-15, 1.4945e-05, 9.9999e-01, 1.0000e+00, 1.0000e+00, 1.0000e+00, 1.0000e+00])
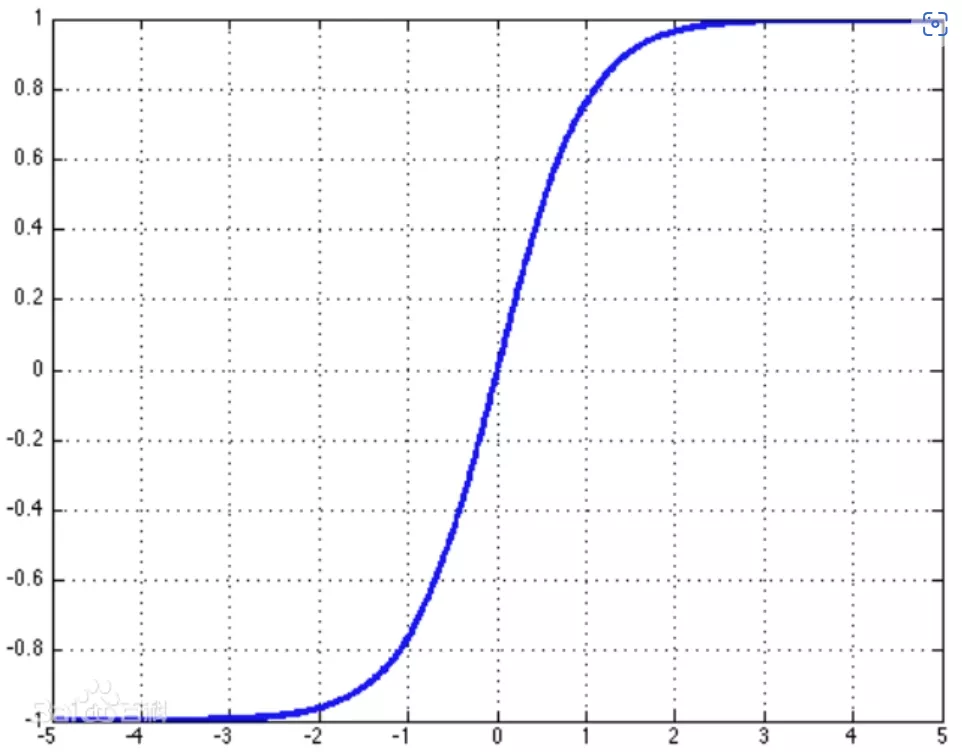
tanh
tanh(x)=ex+e−xex−e−x=2sigmoid(2x)−1
dxdtanh(x)=1−tanh2(x)
在RNN中使用较多。
PyTorch实现
1 2 3 4 5
In [3]: a=torch.linspace(-1,1,10) In [4]: torch.tanh(a) Out[4]: tensor([-0.7616, -0.6514, -0.5047, -0.3215, -0.1107, 0.1107, 0.3215, 0.5047, 0.6514, 0.7616])
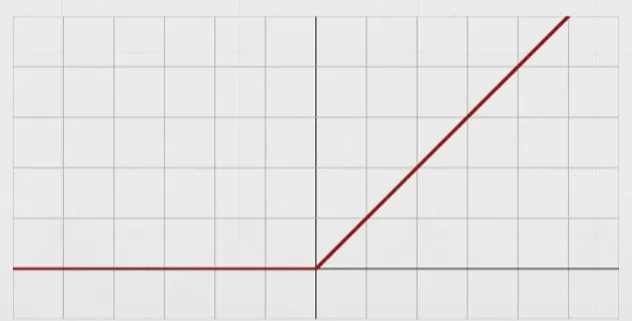
Rectified Linear Unit(ReLU)
f(x)={0forx<0xforx≥0
经过大量实验验证,ReLU函数被证明非常适用于深度学习。
Pytoch实现
1 2 3 4 5 6 7 8 9 10
In [3]: a=torch.linspace(-1,1,10) In [4]: torch.relu(a) Out[4]: tensor([0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1111, 0.3333, 0.5556, 0.7778, 1.0000]) In [5]: a Out[5]: tensor([-1.0000, -0.7778, -0.5556, -0.3333, -0.1111, 0.1111, 0.3333, 0.5556, 0.7778, 1.0000])
Loss函数和梯度
常见的Loss函数
均方差Loss函数(Mean Square Error)
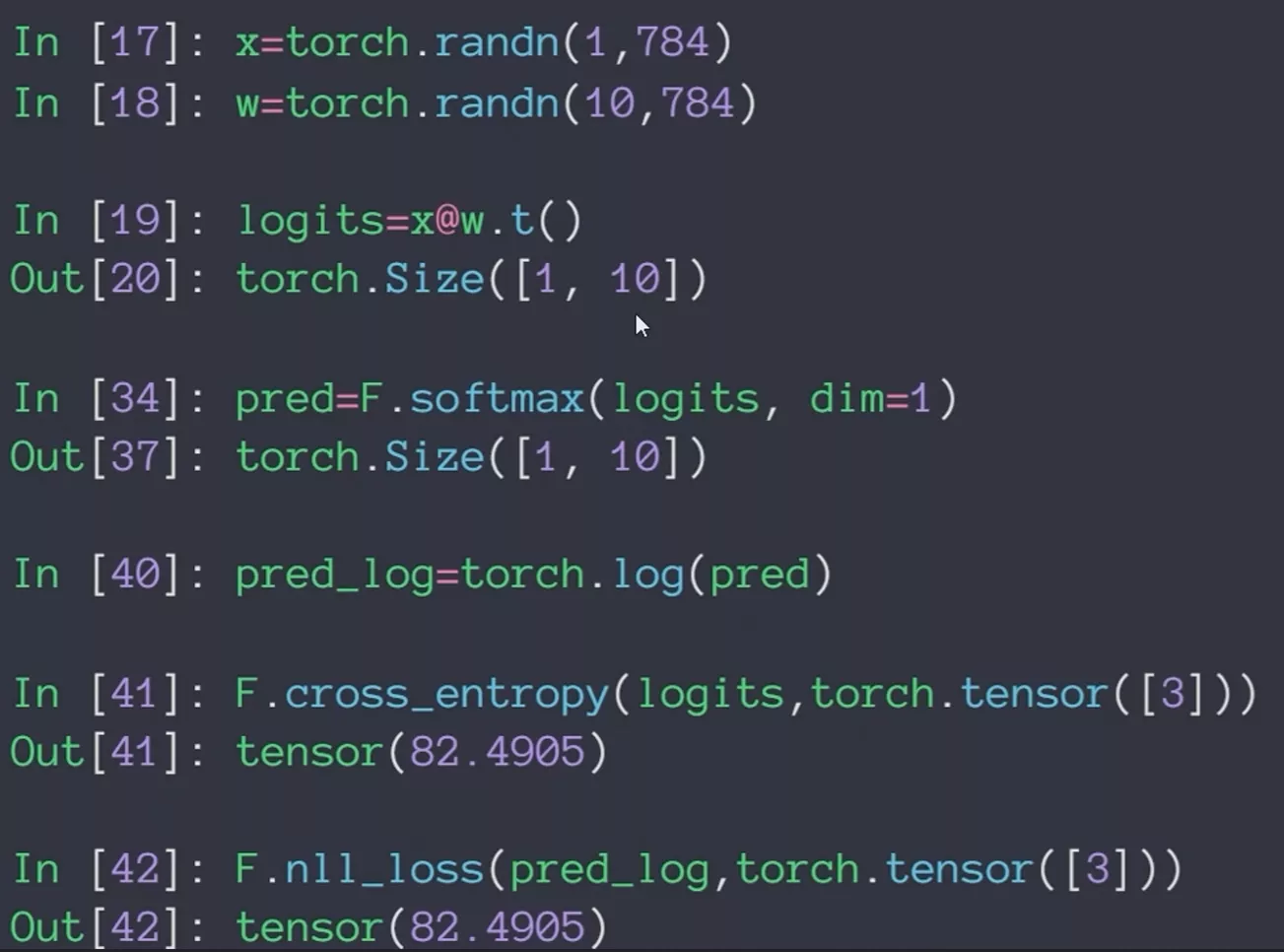
Cross Entropy Loss
二分类(binary)
多分类(multi-class)
softmax
MSE
loss=∑[y−(xw+b)2]
注意和2范数进行区分(L2_norm)
L2_norm=∣∣y−(xw+b)∣∣2
loss=norm(y−(xw+b))2
PyTorch中进行表示结果如下:
1
torch.norm(y-pred,2).pow(2)
对mse函数求导表达式如下:
loss=∑[y−fθ(x)]2
∇θ∇loss=2∑[y−fθ(x)]∗∇θ∇fθ(x)
补充:在PyTorch中实现自动求导※
autograd.grad
1 2 3 4 5 6 7 8 9
In [3]: x=torch.ones(1) In [4]: w=torch.tensor([2.],requires_grad=True)# important In [5]: from torch.nn import functional as F In [6]: mse=F.mse_loss(torch.ones(1),x*w)#label,pred In [7]: mse Out[7]: tensor(1., grad_fn=<MseLossBackward0>) In [8]: torch.autograd.grad(mse,[w]) Out[8]: (tensor([2.]),)
loss.backward※
接上面
1 2 3 4
In [9]: mse=F.mse_loss(torch.ones(1),x*w) In [10]: mse.backward() In [11]: w.grad Out[11]: tensor([2.])
In [3]: a=torch.rand(3) In [4]: a.requires_grad_() Out[4]: tensor([0.1714, 0.4650, 0.7201], requires_grad=True) In [5]: from torch.nn import functional as F In [6]: p=F.softmax(a,dim=0) In [7]: p.sum().backward()# 如果这里不求和,就要在backward中 指定一个和p一样大的tensor,详情见:下面的红色框中的blog In [8]: a.grad Out[8]: tensor([0., 0., 0.]) In [9]: p.grad Out[9]: UserWarning: The .grad attribute of a Tensor that isnot a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (Triggered internally at aten\src\ATen/core/TensorBody.h:417.)
[grad
can be implicitly created only for scalar outputs_](https://blog.csdn.net/qq_39208832/article/details/117415229#:~:text=1.1 grad can be implicitly created only for,是一个 标量 (即它包含一个元素的数据),则不需要为 backward () 指定任何参数,但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。) Ps:这里将p求和,和不将p求和对a求导的最终结果是一样的,因为根据链式法则,最后求和每个p的部分前面的系数都是1,所以乘上1不影响最终的结果。
In [3]: x=torch.randn(1,10) In [4]: w=torch.randn(1,10,requires_grad=True) In [5]: o=torch.sigmoid(x@w.t()) In [6]: o.shape Out[6]: torch.Size([1, 1]) In [7]: from torch.nn import functional as F In [8]: loss=F.mse_loss(torch.ones(1,1),o) In [9]: loss.shape Out[9]: torch.Size([]) In [10]: loss.backward() In [11]: w.grad Out[11]: tensor([[-0.1147, -0.2456, -0.2645, 0.1144, -0.0162, 0.1094, -0.3674, -0.0048, -0.1127, -0.1605]])
然后,我们便可以使用w.grad对w进行更新啦!
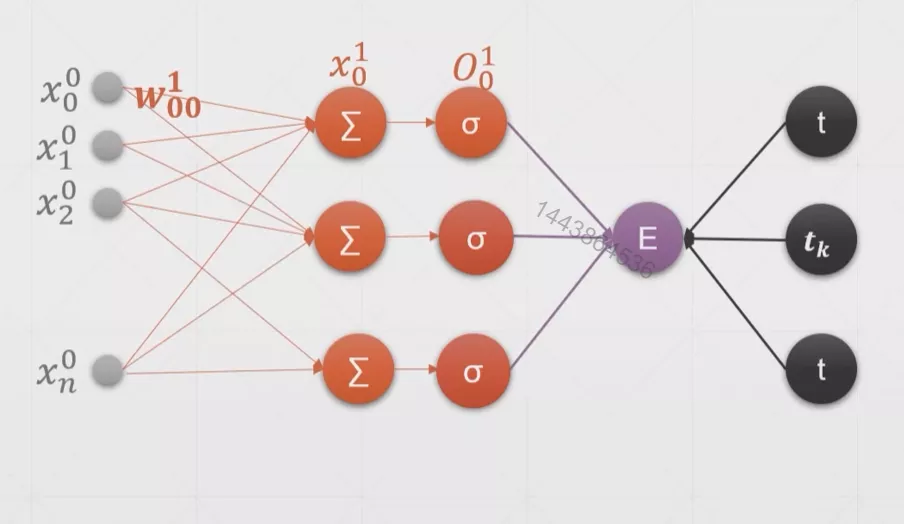
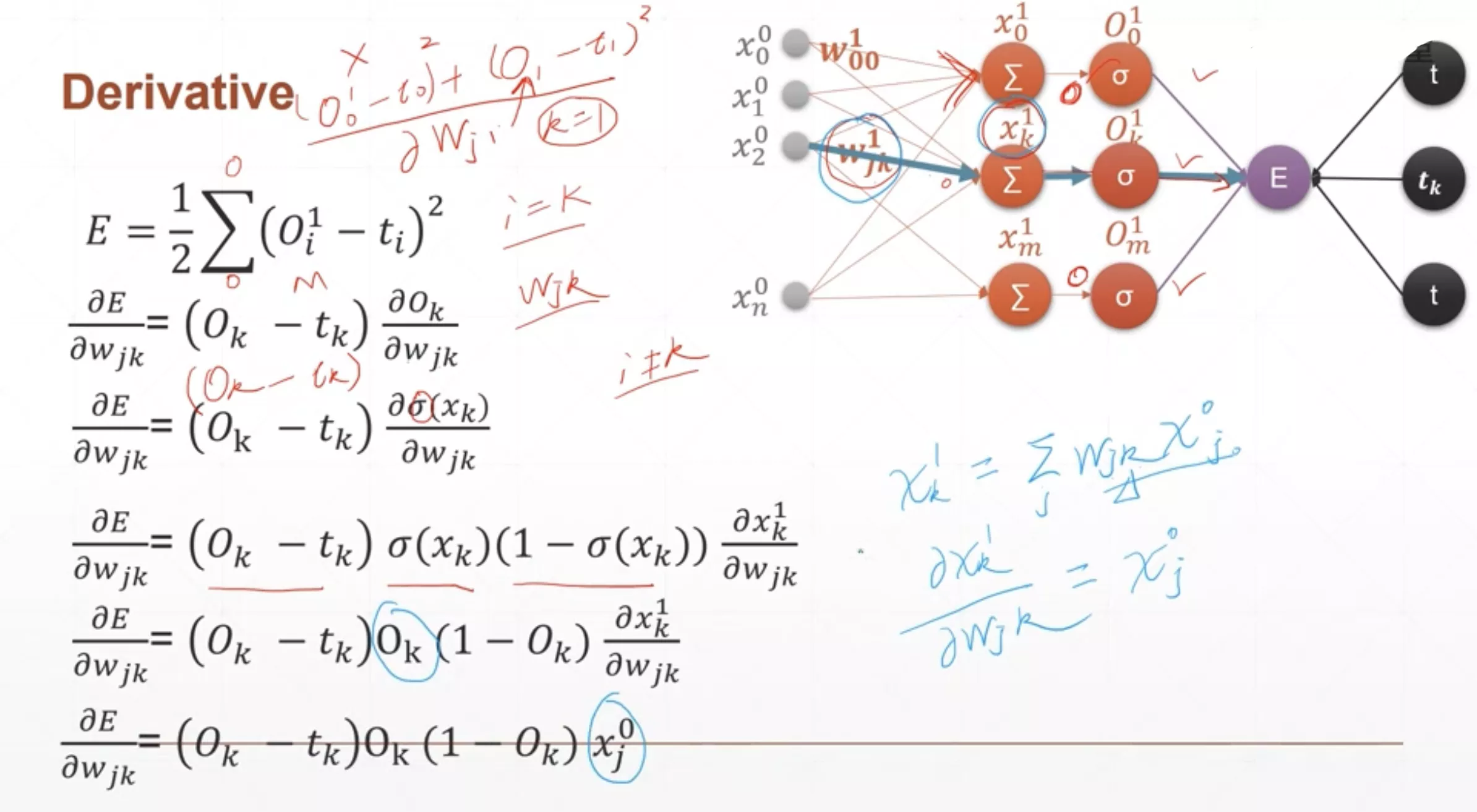
PyTorch多输出感知机实战
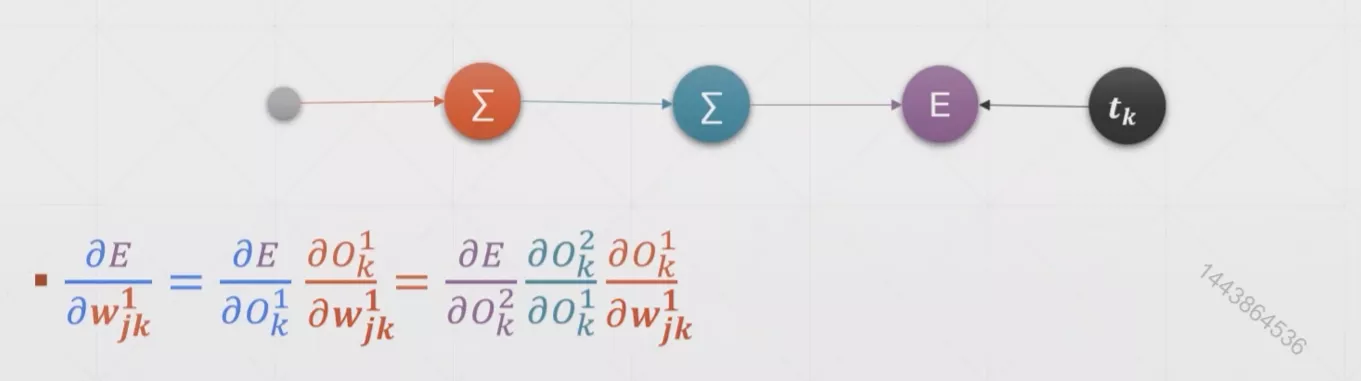
求导推导过程如下:
下面使用PyTorch简单的实现上述单层多输出感知机。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
In [3]: x=torch.randn(1,10) In [4]: w=torch.randn(2,10,requires_grad=True) In [5]: o=torch.sigmoid(x@w.t()) In [6]: o.shape Out[6]: torch.Size([1, 2]) In [7]: from torch.nn import functional as F In [8]: loss=F.mse_loss(torch.ones(1,2),o) In [9]: loss Out[9]: tensor(0.6030, grad_fn=<MseLossBackward0>) In [10]: loss.backward(retain_graph=True) In [11]: w.grad Out[11]: tensor([[-0.1720, -0.1305, -0.0129, 0.0506, -0.0449, 0.1076, 0.0133, 0.0291, 0.0757, 0.0186], [-0.0033, -0.0025, -0.0002, 0.0010, -0.0009, 0.0021, 0.0003, 0.0006, 0.0015, 0.0004]])
In [3]: from torch import autograd In [4]: x=torch.tensor(1.) In [5]: w1=torch.tensor(2.,requires_grad=True) In [6]: b1=torch.tensor(1.) In [7]: w2=torch.tensor(2.,requires_grad=True) In [8]: b2=torch.tensor(1.) In [9]: y1=x*w1+b1 In [10]: y2=y1*w2+b2 In [11]: dy2_dy1=autograd.grad(y2,[y1],retain_graph=True)[0] In [12]: dy1_dw1=autograd.grad(y1,[w1],retain_graph=True)[0] In [13]: dy2_dw1=autograd.grad(y2,[w1],retain_graph=True)[0] In [14]: dy2_dy1*dy1_dw1 Out[14]: tensor(2.) In [15]: dy2_dw1 Out[15]: tensor(2.)