PyTorch - 教程合集
个人PyTorch学习过程中整理归纳的教程,适合入门学习使用✨
因为课程需要学习PyTorch,所以这里就先简单的入个门,使用PyTorch实现一个简单的3层BP全连接神经网络实验。实验使用的数据集是MNIST手写数字识别数据集。

我们设计的网络结构是4层全连接神经网络,因为一个数字所存储的像素信息是因此,网络的第一层有个神经元,第二层设计的有 256个神经元,第三层有64个神经元,第四层有10个神经元。其中第一层和第二层,第二层和第三层,第三层和第四层之间,都有一个relu激活函数。最后第四层的输出向量相当于是对10个数字的识别相似度,最大的数的index代表识别出来相似度最高的数字。
网络构建部分的代码实现如下:
1 | class Net(nn.Module): |
定义损失函数是:
1 | import torch |
这里就是载入了训练集train_loader和test_loader
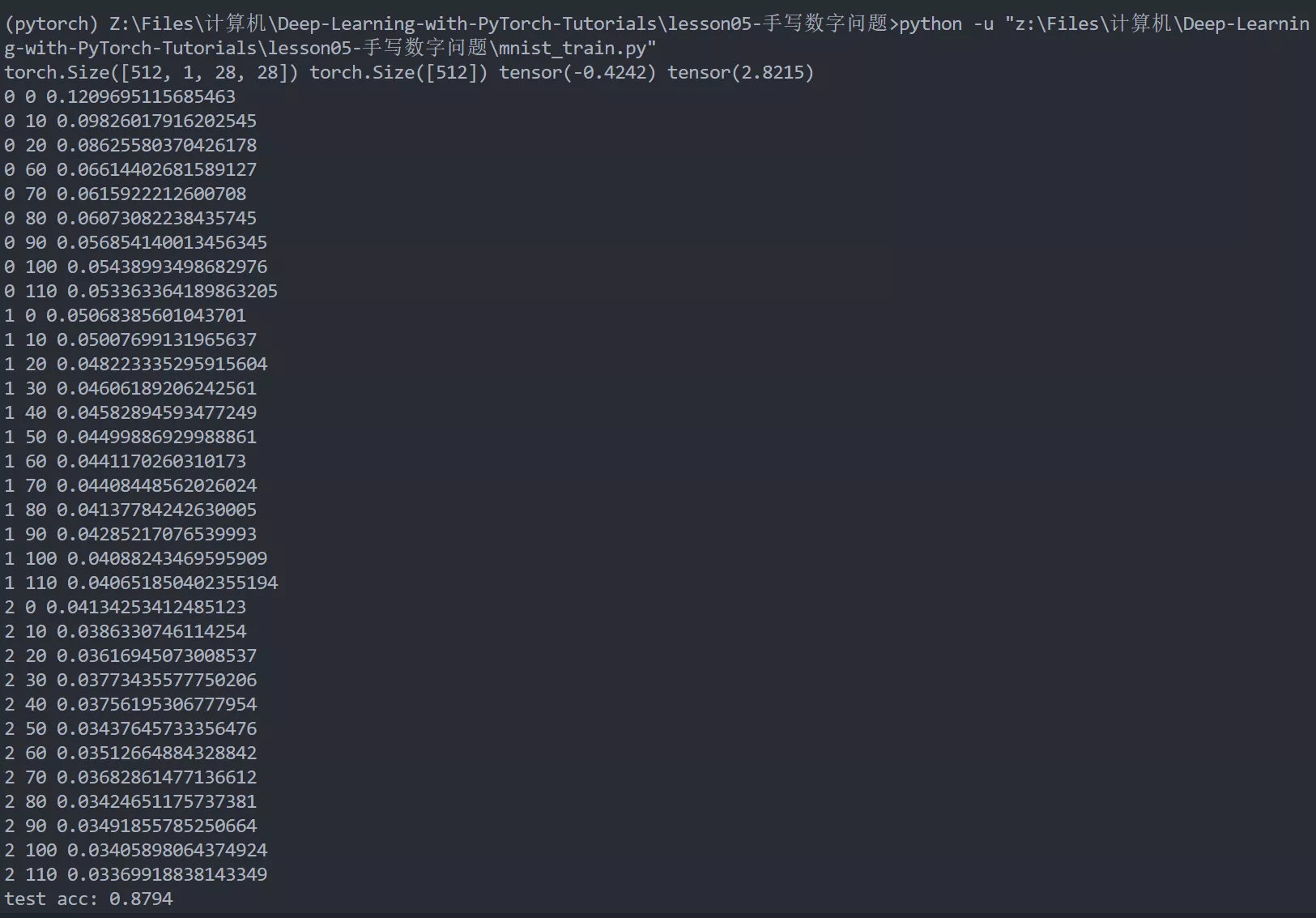
然后倒数第三行的next返回的是训练集中下一个元素(下一个batch),因为是batch大小是512,所以print出来的x和y的维度如下所示。
1 | torch.Size([512, 1, 28, 28]) torch.Size([512]) tensor(-0.4242) tensor(2.8215) |
上面已经进行过讲解了,这里不再赘述
1 | class Net(nn.Module): |
1 | net = Net() # 实例化对象,这里就是我们建立的网络 |
1 | for epoch in range(3): |
epoch代表训练的轮数,这里一共训练三轮。然后每一轮中每次训练取出同一batch下的所有训练数据(一共512组),注释中的b=512
然后先进行reshape。代码中的view实现的功能类似numpy中reshape。这里就将X从一个四维数组转化为了的二维数组。然后扔入网络进行训练,将y标签先转化为独热编码和网络扔出的值结合计算loss。计算结束后就进行以下三步:
1 | optimizer.zero_grad() # 将模型的参数梯度初始化为0 |
总结一下,训练过程的代码一般就以下几块:
1 | optimizer.zero_grad() # 将模型的参数梯度初始化为0 |
然后训练过程就结束了,下面就是测试环节了。
1 | total_correct = 0 |
同理,和训练过程很像,也是先使用view,reshape一下后,扔入网络,得到out后,寻找数值最大的下标记录在pred中,pred就是测试预测的数值,然后就可以计算正确率等评价指标了。
不同于tensorflow的place_holder,pytorch网络定义更加简单便捷,只需要使用类似nn.Linear(a,b)的函数定义连接方式,然后最后实例化网络的时候传入一个parameter()就可以了,相比于tensorflow确实更加简单。
mnist_train.py
1 | import torch |
1 | import torch |

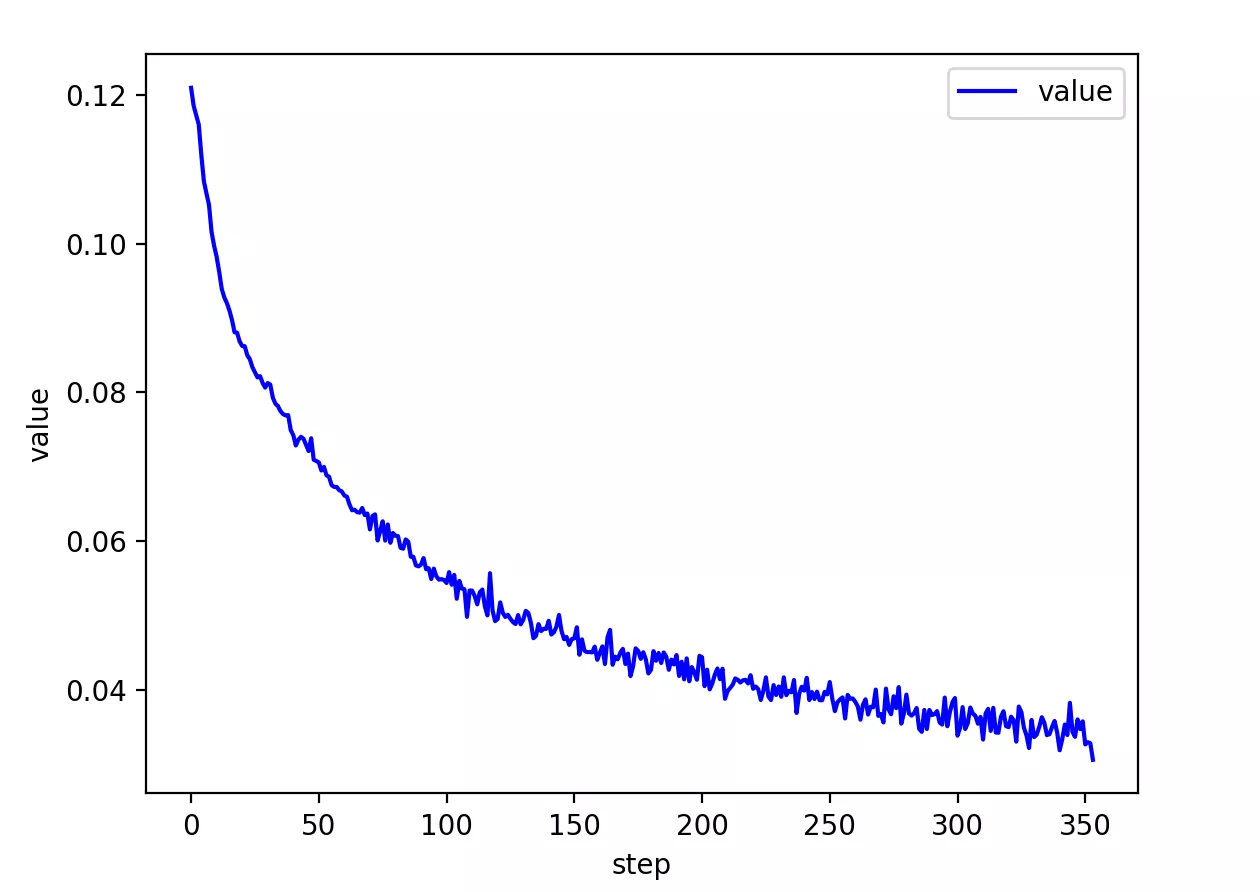

最终可以发现打印出来的均预测正确。acc为0.8794,是可以接受的正确率。